
Barcamp Open Science 2021: neue Perspektiven eröffnen
"Fast so gut wie 'das Echte'" (engl. "Almost as good as ‘the real one’"), lautete das Feedback eines Beitragenden zum siebten Barcamp Open Science, das erstmals komplett online und damit nicht wie üblich in den Räumen von Wikimedia Deutschland in Berlin stattfand. Zusammen mit einigen Session-Moderator:innen geben wir einen Einblick in das Geschehen auf dem diesjährigen Barcamp.
von Sonja Bayer, Tim Boxhammer, Axel Dürkop, Florian Hagen, Emma Anne Harris, Lambert Heller, Juliane Kant, Peter Kraker, Albert Krewinkel, Felicitas Kruschick, Thomas Lösch, Isabella Meinecke, Guido Scherp, Stefan Skupien, Antonella Succurro, Klaus Thoden, Michela Vignoli, Simon Worthington und Philipp Zumstein
Auch in diesem Jahr luden der Leibniz-Forschungsverbund Open Science und Wikimedia Deutschland am 16. Februar zum jährlichen Barcamp Open Science (#oscibar) als Pre-Event der Open Science Conference ein. Aufgrund der Corona-Pandemie wurde das Barcamp zum ersten Mal komplett online abgehalten, und wir konnten rund 100 Teilnehmer:innen versammeln, die ein breites Spektrum an Themen rund um Open Science diskutierten.
Eine allgemeine Beobachtung der letzten Jahre konnte in diesem Jahr bestätigt werden: Etwa die Hälfte der Beitragenden war schon einmal auf einem Barcamp Open Science, für die andere Hälfte war es die erste Teilnahme (und für die weitere Hälfte war es das erste Barcamp überhaupt). Wir haben uns gefreut, dass wir wieder mehr Leute für ein neues Format gewinnen konnten, um den Austausch untereinander zu ermöglichen und eine etablierte Open-Science-Community wachsen zu lassen.
Im Vergleich zu den Barcamps der vergangenen Jahre zeigte sich bei diesem Barcamp Open Science außerdem besonders, dass viele Sessions bereits geplant und gut vorbereitet waren. Allerdings ging es in den durchgeführten Sessions nicht so sehr um Open Science in Zeiten von Corona, was naheliegend gewesen wäre. Aber das Themenspektrum erweitert sich stetig, nicht zuletzt durch den diesjährigen Eröffnungsvortrag von Felicitas Kruschick zum Thema “Wissensungerechtigkeit & Open Science” (engl. “Knowledge Inequity & Open Science”), zu dem sie auch eine Session angeboten hat. Für diesen Blogbeitrag haben sie und viele andere Session-Moderator:innen die Highlights und interessantesten Erkenntnisse vom Barcamp Open Science zusammengefasst.
Privatsphäre bewahrende Open Data
von Antonella Succurro

Privatsphäre bewahrende Open Data
von Antonella Succurro
Die Horizon2020-Leitlinien zu FAIRen Daten (Findable, Accessible, Interoperable und Reusable, PDF) besagen, dass Daten “so offen wie möglich, so geschlossen wie nötig” sein sollen. Wenn es um sensible Daten geht, liegt es dann an den einzelnen Forschenden oder Instituten zu entscheiden, wie sie diese “öffnen”: Sie können sich für einen sehr konservativen Ansatz entscheiden (überhaupt nicht teilen) oder kreative und innovative Wege entwickeln, um sensible Informationen zu teilen. Gängige Praktiken zur Wahrung der Privatsphäre bei der gemeinsamen Nutzung von Daten sind Datenanonymisierung und Datenaggregation, aber beide Ansätze können Herausforderungen mit sich bringen. Im ersten Fall besteht die Gefahr der De-Anonymisierung, zum Beispiel durch Querverweise mit zusätzlichen Daten. Im zweiten Fall ist die Gefahr, dass einige Informationen identifiziert werden, umso größer, je mehr aggregierte Statistiken gesammelt werden.
In dieser Barcamp-Session wurde deutlich, dass die Unterstützung durch Datenschutzbeauftragte oder externe Sachverständige oft nicht ausreicht, um die Herausforderungen hochspezifischer Daten zu bewältigen, die möglicherweise aus neuen Technologien stammen und noch nicht standardisiert sind. Zum Beispiel gelten Genomikdaten als unmöglich zu anonymisieren, ohne dabei den biologischen Wert für Forschungszwecke zu verlieren Wir brauchen daher eine koordinierte Anstrengung zum Aufbau von Infrastrukturen, die Schulungen und Dienstleistungen für vereinheitlichte “Best Practices” für den Datenaustausch innerhalb des rechtlichen Rahmens der Datenschutz-Grundverordnung (DSGVO) anbieten.
Session pad
Custom Services von Open Knowledge Maps
von Peter Kraker und Michela Vignoli

Custom Services von Open Knowledge Maps
von Peter Kraker und Michela Vignolio
Heute stehen wir vor einer „Discoverability-Krise“, die es schwer macht, auf dem neuesten Stand der Forschung zu bleiben. Open Knowledge Maps (OKMaps) ist ein offenes visuelles Entdeckungswerkzeug, das auf Wissenskarten basiert und Forschende, Studierende und Praktiker:innen bei der Suche nach relevantem wissenschaftlichen Wissen unterstützt. Als eine von der Community getriebene Organisation bezieht OKMaps dabei die breitere Nutzer:innengemeinschaft schon früh in die Entwicklungsphase ein.
In diesem Sinne lud das OKMaps-Team die Teilnehmer:innen des Barcamps Open Science ein, erste Ideen für die brandneuen ‚Custom Services‘ von OKMaps zu diskutieren. Die anpassbaren Cloud-Dienste werden in die Discovery-Dienste der Bibliotheken eingebettet, um unmittelbar Funktionen zur Visualisierung hinzuzufügen. Die Teilnehmenden der Session reagierten positiv auf dieses Konzept und schlugen weitere interessante Anwendungsfälle vor. Einer davon war die Integration von Wissenskarten mit institutionellen Forscher:innenprofilen, um eine visuelle Darstellung der verfassten Publikationen hinzuzufügen. Ein anderer Vorschlag war, Wissenskarten zu nutzen, um Lesevorschläge für Studierende anzuzeigen, um eine übersichtlichere Alternative zu verwirrend langen Listen zu haben.
Der Input aus der Community hat dem OKMaps-Team ungemein geholfen, das Design der Custom Services den Bedürfnissen der Nutzenden weiter anzupassen. Die Custom Services werden durch das Open-Knowledge-Maps-Fördermitgliedschaftsprogramm finanziert. Unterstützende Mitgliedsorganisationen sind direkt in den Entscheidungsprozess von Open Knowledge Maps eingebunden. Mehr Informationen über das Programm finden sich auf der OKMaps-Website. Kontaktieren Sie uns gerne, wenn Sie sich beteiligen möchten, per E-Mail an info (at) openknowledgemaps.org oder über Twitter @OK_Maps
Session pad
Wissensungerechtigkeit & Open-Science-Kriterien
als ein Ausweg davon?
von Felicitas Kruschick

Wissensungerechtigkeit & Open-Science-Kriterien als ein Ausweg davon?
von Felicitas Kruschick
Führt Open Science automatisch zu Wissensgerechtigkeit? In dieser Barcamp-Session diskutierten wir diese Frage und fanden heraus, dass es nicht so einfach ist. Es ist wichtig, immer wieder über die Machtdynamik nachzudenken, in der jede:r ihr:sein Projekt und die eigene Arbeit analysieren und diskutieren muss (was zum Beispiel aus Zeitgründen als nicht so einfach angesehen wurde). Wer profitiert wie von den Projekten und wer nicht? Wer führt durch theoretische Diskurse und warum? Wessen Stimmen werden gehört und wessen bleiben stumm und warum? Jede:r muss sich die Frage stellen: Wer bleibt auf der Strecke und auf welche Weise? Nur wenn jede:r kontinuierlich über diese Fragen nachdenkt, was zu unterschiedlichen Antworten für unterschiedliche Kontexte und Realitäten führt, kann sich jede:r der Herausforderung der Wissensgerechtigkeit stellen.
Zudem darf die Frage der Adressierung nie vergessen werden. Wer adressiert wen in welchem Kontext? Wer ist mit “wir” und wer mit “die anderen” gemeint? Denkt man an Saids Theorie des Orientalismus, wird deutlich, dass die Frage nach Wissensungerechtigkeit nur im Kontext von Macht gestellt werden kann, was unmittelbare Konsequenzen für die Adressierung der ‘Anderen’ hat. Ob im Kontext von Wissenschaft und Forschung, Politik oder Wirtschaft, international oder lokal – wenn von einem ‘Wir’ ausgegangen wird, manifestiert sich ein:e ‘Andere:r’, was auf der manifesten Ebene zu einer Verstärkung von Ungerechtigkeit führen kann. Eines der Hauptergebnisse der Session war daher, dass man nie aufhören sollte, sich zu fragen, welche Position man in welchem Kontext einnimmt und wer dabei abgewertet wird. Als ebenso unzweifelhaft erwies sich, dass die Frage nach der Wissensungerechtigkeit als Dilemma gesehen werden muss, da Wissensgerechtigkeit nie vollständig erreicht werden kann.
Ein zweiter wichtiger Punkt war die Frage, warum Wissenschaft und Forschung nicht mehr mit Open-Science-Kriterien “arbeiten”. Es wurde angemerkt, dass die Wissenschaft als in ‘alten’ Infrastrukturen festhängend wahrgenommen wird. Es erfordert Anstrengung und Mut, diese alten Vorstellungen, die unserer Meinung nach auf finanziellen Aspekten und Reputation, aber auch auf einer großen Unsicherheit über die Aufrechterhaltung der wissenschaftlichen Qualität beruhen, aufzubrechen und neue Ideen einzuführen. Wir haben auch festgestellt, dass die Open-Science-Affinität wahrscheinlich von Fachbereich zu Fachbereich unterschiedlich ist. In sozialwissenschaftlichen Fächern ist die Nutzung von Open Science beispielsweise weniger etabliert, da hier oft mit dem Argument der Sensibilität von Daten gearbeitet wird.
Session pad
Zum Weiterlesen:
(Wieder-)Verwendung verfügbarer Forschungsdaten in den
Sozial-, Erziehungs-, Verhaltens- und Wirtschaftswissenschaften
von Thomas Lösch und Sonja Bayer

(Wieder-)Verwendung verfügbarer Forschungsdaten in den Sozial-, Erziehungs-, Verhaltens- und Wirtschaftswissenschaften
von Thomas Lösch und Sonja Bayer
Mit der (Wieder-)Verwendung vorhandener Forschungsdaten ist gemeint, dass Forschungsdaten, die zum Beispiel von Forschungsdatenzentren zur Verfügung gestellt werden, auf eine Weise genutzt werden, die bei der Erhebung dieser Daten nicht unbedingt beabsichtigt war. Die (Wieder-)Verwendung von Daten hat dabei viele Vorteile, da sie das Potenzial von Open/FAIR Data durch eine gute Nutzung der verfügbaren Ressourcen realisiert.
Die Session sollte einen Überblick über den aktuellen Stand geben. Werden Daten genutzt? Was funktioniert, was nicht und warum?
Wir identifizierten hauptsächlich Hindernisse und einige Voraussetzungen für die (Wieder-)Verwendung von Forschungsdaten:
- Forschungsdaten müssen gut dokumentiert sein, damit die (Wieder-)Verwender:innen sehen können, wie die Daten entstanden sind – insbesondere im Hinblick auf Nuancen in unterschiedlichen Laboren oder Communities ( zum Beispiel leicht unterschiedliche Wege, dieselbe Sache zu messen). Dies ist sogar noch relevanter, wenn verfügbare Daten interdisziplinär (wieder-)verwendet werden.
- Ein zentraler Zugangspunkt zu Forschungsdaten hilft Forschenden sehr dabei, nützliche Daten zu finden – dies ist zum Beispiel in der Astrophysik der Fall.
- – Richtlinien von Förderorganisationen sowie Antragsverfahren sollten die (Nach-)Nutzung von Daten als Standardmöglichkeit zulassen.
- – Darüber hinaus können Förderorganisationen die Wiederverwendung von Daten fördern, indem sie diesen Punkt in ihre Antragsformulare mit aufnehmen. Zum Beispiel könnte in Antragsformularen für Zuschüsse ausdrücklich eine Erklärung gefordert werden, welche verfügbaren Daten verwendet werden (oder warum neue Daten gesammelt werden müssen). Außerdem könnten Förderorganisationen direkt auf vertrauenswürdige Repositorien verweisen.
- – In wissenschaftlichen Communities wird die (Wieder-)Verwendung von Daten oft nicht so sehr geschätzt wie das Sammeln von Daten selbst. Manchmal wird es als innovativer angesehen, Daten auf eine erstaunliche neue Weise zu sammeln.
Eine Gelegenheit, tiefer in das Thema einzutauchen, könnte sich im September 2021 bieten, für den wir planen, ein Barcamp zum Thema (Wieder-)Verwendung von Forschungsdaten zu organisieren.
Session pad
Wie lassen sich offene Wissenschaftler:innen
an Universitäten unterstützen?
von Philipp Zumstein

Wie lassen sich offene Wissenschaftler:innen an Universitäten unterstützen?
von Philipp Zumstein
Forscher:innen beim Zugang zu Informationen zu unterstützen oder sie mit Hard- und Software zu versorgen, sind traditionelle Dienstleistungen für Bibliotheken oder IT-Service-Einheiten innerhalb einer Universität oder anderer Institutionen. Wenn Forschende Open Science praktizieren, haben sie möglicherweise weiteren Bedarf an Unterstützung, und das war das Thema dieser Sitzung.
Als Ergebnis einiger schneller Einstiegsfragen unter den Teilnehmer:innen sehen wir einige Hinweise darauf, welche Aspekte des Open-Science-Supports wichtig sind und wie viel Unterstützung es derzeit gibt:

Es gibt mehrere Bereiche von Open Science, für die es an institutioneller Unterstützung mangeln kann. Es wurde diskutiert, dass Zuständigkeiten innerhalb einer Institution (beispielsweise sollte es für Open Access die Bibliothek sein) entscheidend für die Etablierung von Open-Science-Diensten sind. So stellt sich auch die Frage: Wer ist für die Unterstützung von offenen Wissenschaftler:innen bei der Präregistrierung von Studien zuständig? Eine strategische Planung für eine Universität sollte auch die fachspezifischen Bedürfnisse aus den Forschungsbereichen berücksichtigen. Viele weitere Dinge wurden in dieser ergebnisreichen Diskussion angesprochen und hilfreiche Links angegeben. Weitere Details verrät das Session Pad.
Session pad
Diskussion von Ansätzen des Single Source Publishings
in Lehre und Forschung | Community Networking
von Tim Boxhammer, Axel Dürkop, Florian Hagen, Albert Krewinkel,
Isabella Meinecke, Klaus Thoden und Simon Worthington
Diskussion von Ansätzen des Single Source Publishings in Lehre und Forschung | Community Networking
von Tim Boxhammer, Axel Dürkop, Florian Hagen, Albert Krewinkel, Isabella Meinecke, Klaus Thoden und Simon Worthington
Ziel unserer Session war es, Stakeholder:innen aus der Open-Science-Community zu vernetzen, die aktiv an Single Source Publishing (SSP) arbeiten oder stark daran interessiert sind. SSP ermöglicht es, verschiedene Ausgabeformate (zum Beispiel HTML, PDF, JATS/XML) aus nur einer einzigen Quelle (wie Markdown oder XML) zu erzeugen. Drei Ansätze – im Folgenden kurz aufgeführt – wurden vorgestellt und diskutiert. Neueinsteiger:innen und Expert:innen definierten die Vorteile von SSP mit dem Fokus auf die verschiedenen Aspekte des Forschungslebenszyklus.
In der Session wurden drei Projekte vorgestellt:
- Am TIB Open Science Lab arbeiten Simon Worthington und Kolleg:innen am semantischen Publizieren für Architektur, wo sie versuchen, eine Vielzahl von Datenquellen und komplexen digitalen Objekten in einer Lehrbuchpublikation zusammenzuführen. Der Forschungskontext liegt im deutschen Konsortium der nationalen Forschungsdateninfrastruktur für Kultur (NFDI4Culture), in dem ein Konsortium fortschrittliche offene Infrastrukturen zusammenführt, zum Beispiel: Wissensgrafen, IIIF Deep Image Zoom, Wikidata und die Anzeige kontextbezogener Daten (Proactive Information Delivery – PID) in 3D-Punktwolken und Videos. Siehe auch das GitHub Repo: ADA – Semantic Publishing.
- Klaus Thoden stellte die Edition Open Access Publication Infrastructure vor, die TEI-XML als Hauptdokumentenformat für ihre SSP-Workflows verwendet. Er betonte, dass es bei SSP wichtig ist, sicherzustellen, dass das Quellformat das vollständigste Format ist. Das heißt, es enthält alle notwendigen Auszeichnungs- und Metadaten. Die endgültigen Publikationsformate wie PDF, EPUB oder eine Online-Version werden aus dieser Quelle erstellt und können als verlustbehaftete Versionen betrachtet werden, die lediglich ihren speziellen Zweck erfüllen.
- Axel Dürkop gab schließlich eine kurze Einführung in Swapfire, einem Ansatz der Technischen Universität Hamburg-Harburg (TUHH) und der Staats- und Universitätsbibliothek Hamburg. Es handelt sich um ein modulares System, das im Rahmen des Projekts Modernes Publizieren entwickelt wurde, aus GitLab und Open Journal Systems (OJS) besteht und von Pandoc/Pandoc Scholar (Multiformat-Konverter) und Hypothes (Annotationen) unterstützt wird. Das System ist ein effektiver und in hohem Maße anpassbarer Ansatz, um verschiedene Ausgabeformate aus einer einzigen Quelle zu erzeugen.
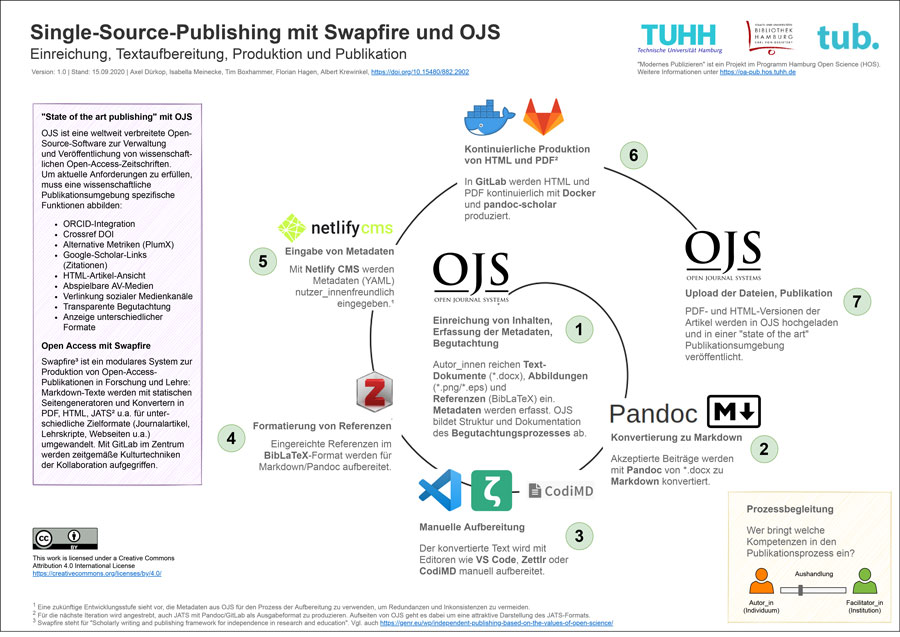
Darstellung eines Workflows für Single-Source-Publishing mit Markdown, Gitlab, pandoc und OJS. (CC BY 4.0).
Im Anschluss an die Kurzpräsentationen fand eine Diskussion der Teilnehmenden statt. Es wurde der Wunsch geäußert, mehr praktisches Material für den Einstieg zu haben. Schließlich wurde die Idee, eine Community zu SSP aufzubauen, unterstützt.
Wie kann man sich in Zukunft beteiligen? Kontakt: E-Mail an oa-pub.hos(at)tuhh.de oder werfen Sie einen Blick auf das Session Pad.
Session Pad
Zu Ihren (Daten-)Diensten: Wie können wir das
„Forschungsdatenmanagement-Service-Portfolio“ erweitern?
von Emma Anne Harris

Zu Ihren (Daten-)Diensten: Wie können wir das „Forschungsdatenmanagement-Service-Portfolio“ erweitern?
by Emma Anne Harris
Es gibt viele Diskussionen über den Ausbau von Forschungsdatenmanagement-Diensten (FDM-Diensten) aus der Perspektive der Forschenden. Aber auch das Verständnis und die Unterstützung von Dienstleistenden ist entscheidend für die Verankerung von Open- und FAIR-Data-Ansätzen in Institutionen.
Die Sitzung identifizierte einige klare Trends, was angeboten wird und was nicht. Die Teilnehmer:innen stellten fest, dass Beratung zu Datenmanagementplänen (DMPs), allgemeine Schulungen zu FDM und Unterstützung bei der Archivierung zu den üblichen Dienstleistungen gehören, die angeboten werden. Rechtliche Beratung und Unterstützung zu sensiblen Daten, wie zu den Bestimmungen der Datenschutz-Grundverordnung sowie Informationen zu Kollaborations- und Repository-Tools, wie Comma Soft oder das RIN-Datenrepository, wurden hingegen als Dienstleistungen identifiziert, von denen die Teilnehmer:innen sich wünschten, dass sie angeboten würden. Zeit, Arbeitsbelastung, Personal und mangelnde institutionelle Akzeptanz wurden als Hindernisse für die Bereitstellung von mehr FDM-Diensten genannt.
In der abschließenden Diskussion ging es darum, wie die Teilnehmenden ihr Dienstleistungsportfolio ausbauen könnten. Man war sich einig, dass eine grundlegende FDM-Strategie hilfreich wäre. Mehrere Teilnehmer:innen betonten, dass bessere Verbindungen zwischen den Abteilungen, zum Beispiel zwischen Bibliothek und IT, hilfreich wären, obwohl diese vorsichtige und schrittweise Verbesserungen erfordern. Zusätzliche finanzielle und personelle Mittel wären ebenfalls eine enorme praktische Hilfe. Andere schlugen vor, dass Forschende selbst in der Lage sein könnten, Unterstützung und Fachwissen bei der Schaffung von Diensten anzubieten, die das FDM-Angebot erweitern, und dass in der Tat Bottom-up- oder Graswurzel-Initiativen, wie openmod, langfristig eher verankert werden können. Die Ergebnisse dieses Workshops werden in das FDNext-Projekt einfließen, das Ressourcen zur Unterstützung von Dienstleistenden bei der konkreten Einschätzung und Erweiterung ihrer FDM-Dienste erstellen wird.
Session Pad
Publikationsinfrastrukturen,
die die Reproduzierbarkeit unterstützen
von Juliane Kant
Publikationsinfrastrukturen, die die Reproduzierbarkeit unterstützen
von Juliane Kant

Reproduzierbarkeit und Transparenz können (zumindest in der experimentellen Forschung) als ein Markenzeichen der Forschung angesehen werden. Die Fähigkeit, Forschungsergebnisse unter Verwendung der Originaldaten und -verfahren (zum Beispiel: Code) zu reproduzieren, hilft, auf vorhandenem Wissen aufzubauen. Trotz der Tatsache, dass die meisten Forscher:innen darin übereinstimmen, dass Reproduzierbarkeit und Transparenz wünschenswerte Ziele und Teil einer guten Forschungspraxis darstellen, sind Bemühungen zur Verbesserung der Reproduzierbarkeit immer noch nicht Teil des Forschungsalltags.
In dieser Sitzung wurde diskutiert, was Forschende benötigen, um ihre Ergebnisse reproduzierbar zu veröffentlichen und wie Infrastrukturen diesen Prozess unterstützen können. Die Teilnehmer:innen erwähnten, dass Forschende Infrastrukturen benötigen, die einfach zu bedienen sind, sich nahtlos in ihre Routineabläufe einfügen, kostenlos sind und idealerweise Open Source. Als Beispiele wurden langfristige interaktive Notebooks, Repositorien für Code, elektronische Laborbücher und Plattformen, die Daten, Code und Publikationen verknüpfen, genannt. Diese Infrastrukturen sollten auf gemeinsamen Standards beruhen und bestehende Werkzeuge wie GitHub oder GitLab, Zenodo und R Markdown integrieren. Außerdem sollte die kontinuierliche Verfügbarkeit gewährleistet sein. Darüber hinaus wurde eine lokale Unterstützung der Forscher:innen als notwendig erachtet, zum Beispiel im Hinblick auf das Datenmanagement. Schließlich sind Anreize und Zeit wesentliche Voraussetzungen für reproduzierbare Praktiken. Die Ergebnisse aus dieser Sitzung werden in ein Projekt der europäischen Initiative Knowledge Exchange zum Veröffentlichen von reproduzierbaren Forschungsergebnissen.
Session Pad
Open Science bei Wahlen - Politik
in Wahlperioden einbeziehen
von Stefan Skupien
Open Science bei Wahlen – Politik in Wahlperioden einbeziehen
von Stefan Skupien

2021 ist “Superwahljahr” in Deutschland, wo mehrere Wahlen auf Bundes- und Landesebene stattfinden. Da die Wissenschaft zunehmend Teil der öffentlichen Diskussion ist und die aktuelle Pandemie genutzt wird, um den Erfolg von Open-Science-Praktiken zu präsentieren, stellt sich die Frage, ob man sich mit Politik befassen sollte, um mehr Unterstützung für Open-Science-Policies auf Bundes- und Landesebene zu erhalten.
Wahlen könnten mehr Aufmerksamkeit auf das Thema lenken und die Parteien dazu zwingen, offene und qualitativ hochwertige Wissenschaft in ihre Programme aufzunehmen. Vergangene Wahlen haben zum Beispiel zum Wissenschaftsbarometer als Instrument zur Überprüfung der Wissenschaftspolitik im Allgemeinen geführt. Ist dies im Jahr 2021 replizierbar?
In dieser Session diskutierten wir das Thema und stellten fest, dass es sowohl nationale Empfehlungen für Open Science (zum Beispiel für Österreich) als auch die aktuelle Unterstützung der EU und der UNESCO für die Umsetzung von Open-Science-Praktiken und –Policies gibt. Wir waren jedoch vorsichtig, was die unterschiedlichen Motivationen zur Unterstützung von Open Science sowie das fehlende Bewusstsein und die fehlende Priorität für Wissenschaft/Open Science bei politischen Entscheidungsträger:innen betrifft. Auf nationaler und lokaler Ebene gibt es eine Vielzahl von Netzwerken, die sich ebenfalls auf die Wissenschaftspolitik für ein offeneres und faireres Wissenschaftsökosystem konzentrieren. Wir planen, uns über lokale Initiativen auf dem Laufenden zu halten (zum Beispiel die innObeers: monatlicher Open Science & Open Innovation in Science Stammtisch für Open-Science-Koordinator:innen in Berlin).
Session Pad
Zum Weiterlesen:
Bundesweit agierende Netzwerke, die auch die Politik beeinflussen (und sich für hochschulpolitische Aspekte einsetzen).
Fazit: Wir brauchen mehr Barcamps zu Open Science
Eine unserer zentralen Erkenntnisse aus dem Barcamp Open Science 2021 ist: Barcamps funktionieren auch online, wenn auch anders. Das hat man schon bei anderen Barcamps zu Open Science gesehen, etwa dem Barcamp auf dem Open Science Festival oder auf dem Barcamp@GeNeMe’2020. Den Vorteilen, wie der einfachen Teilnahme, stehen natürlich auch Nachteile gegenüber, wie weniger Möglichkeiten zum direkten Austausch. Und online muss man einfach Abstriche machen, weil die Teilnahme anstrengender ist. Aber online wie offline sind Barcamps ein tolles Austausch- und Vernetzungsformat. Man kann voneinander lernen.
Wir werden zunehmend nach unseren Erfahrungen bei der Durchführung eines Barcamps gefragt, die wir gerne teilen. Wir sind offen für Kooperationen und freuen uns darauf, weitere Barcamps rund um Open Science zu veranstalten. Schauen Sie einfach regelmäßig auf der Barcamp Open Science Website nach Updates und/oder nehmen Sie direkt Kontakt mit uns oscibar(at)zbw.eu oder mit Guido (g.scherp(at)zbw.eu) oder Lambert (lambert.heller(at)tib.eu) auf.
Eine Übersicht über alle Sessions und die jeweilige Dokumentation finden Sie auch in diesem Cryptpad.
Links zum Barcamp Open Science
- Website Barcamp Open Science
- Kontakt zu den Organisator:innen des Barcamps Open Science
- Auf dem Laufenden zu Open Science und dem Barcamp bleiben: mit dem ZBW MediaTalk Newsletter!
- Hashtag #oscibar
Mehr Tipps für und Artikel zu Veranstaltungen
- Barcamp Open Science 2021: Ein GenR-Report
- Open Science Conference 2021: Auf dem Weg zum “New Normal”
- Barcamp Open Science 2020: Lernen, wie man etwas bewegt
- Open Science & Libraries 2021: 21 Tipps für Konferenzen, Barcamps & Co
- ZBW MediaTalk-Veranstaltungskalender für weitere spannende Events in den kommenden Monaten
- Open Science Conference 2019: Jetzt werden die Empfehlungen umgesetzt
- Open Science Conference 2018: Auf dem Weg in die Praxis!
Das könnte Sie außerdem interessieren
- Open Science und Organisationskultur: Offenheit als Kernwert in der ZBW
- Open-Science-Podcasts: 7 + 3 Tipps für die Ohren
- Digitale Open-Science-Tools: mehr Offenheit durch inklusives Design
- Scoping the Open Science Infrastructure Landscape in Europe
This text has been translated from English.
Über die Autor:innen
Dr. Sonja Bayer arbeitet als Senior Researcher am DIPF | Leibniz-Institut für Bildungsforschung und Bildungsinformation und koordiniert den Verbund Forschungsdaten Bildung (VerbundFDB). Ihr Interesse gilt der Forschung zum Lehren und Lernen, Open Science, Forschungsdatenmanagement, Data Science. Sie ist auch auf ORCID and Twitter zu finden.
Porträt: Sonja Bayer©
Dr. Tim Boxhammer ist promovierter, auf Klimaforschung spezialisierter Meereswissenschaftler. Er ist ein Verfechter von Open Science und war Teammitglied des Projekts Modernes Publizieren. Seinen Hintergrund nutzt er, um die Bedürfnisse der wissenschaftlichen Community zu definieren. Seit 2021 implementiert er eine neue Stufe des wissenschaftlichen Zeitschriftenhostings an der Staats- und Universitätsbibliothek Hamburg. Er ist auch auf ORCID und ResearchGate zu finden.
Axel Dürkop hat seine Wurzeln in der Philosophie und im Theater. Er arbeitet für die Hamburg Open Online University (HOOU) am Institut für Technische Bildung und Hochschuldidaktik (iTBH) der Technischen Universität Hamburg-Harburg (TUHH) an der Gestaltung von Open Education und Open Science. Er war Teamleiter und Entwickler für das Projekt Modernes Publizieren an der TUHH-Bibliothek im Programm Hamburg Open Science (HOS).
Florian Hagen arbeitet als Fachreferent mit Schwerpunkt Open Access und Open Education an der Universitätsbibliothek der Technischen Universität Hamburg-Harburg (TUHH). Zuvor war er an der TUHH an verschiedenen Projekten aus Programmen wie Hamburg Open Science (HOS) und Hamburg Open Online University (HOOU) beteiligt und an der ZBW Hamburg für die Ausbildung von Fachangestellten für Medien- und Informationsdienste zuständig.
a href=”https://eitrawmaterials.eu/about-us/people/team/” target=”_blank” rel=”noopener noreferrer”>Emma Anne Harris arbeitete an der Humboldt-Universität zu Berlin an dem Projekt FDNext, das sich auf die Unterstützung und Verbesserung von Forschungsdaten-Praktiken in Deutschland konzentriert. Sie ist auch auf LinkedIn und Twitter zu finden.
Porträt, Fotografin: Anya Shvetsova©, CC-BY-NC
Emma Anne Harris has worked at Humboldt-Universität zu Berlin on the FDNext project which focuses on supporting and improving RDM practices in Germany. She can also be found on LinkedIn and Twitter.
Portrait, photographer: Anya Shvetsova©, CC-BY-NC
Als Sozialwissenschaftler und wissenschaftlicher Bibliothekar gründete Lambert Heller 2013 das Open Science Lab (OSL) an der TIB – Leibniz-Informationszentrum Technik und Naturwissenschaften und Universitätsbibliothek. Mit NFDI4culture, Open Research Information, Decentralized Web Applications und anderen gef/u00f6rderten Projekten unterstützt das OSL Communities in Wissenschaft und Kultur bei der Einführung offener digitaler Werkzeuge und Praktiken. Er ist auch auf LinkedIn und Twitter zu finden.
Porträt: Lambert Heller©
Dr. Juliane Kant ist Programm-Managerin bei der Deutschen Forschungsgemeinschaft (DFG). Sie ist im Bereich Open Access und Digitales Publizieren tätig und betreut zusammen mit ihren Kolleg:innen das Förderprogramm Infrastrukturen für wissenschaftliches Publizieren. Darüber hinaus ist sie Partnervertreterin in der europäischen Initiative Knowledge Exchange und leitet Arbeitsgruppen im Bereich Open Science und Open Access.
Porträt: Juliane Kant©
Dr. Peter Kraker ist Gründer und Vorsitzender von Open Knowledge Maps Open Knowledge Maps. Als langjähriger Verfechter von Open Science ist er bekannt für die Prägung des Begriffs “Open Methodology” und für seine führende Rolle beim Erstellen der “Vienna Principles – A Vision for Scholarly Communication in the 21st Century”. Er ist auch auf Twitter zu finden.
Porträt: Peter Kraker©, CC BY 4.0
Albert Krewinkel ist ein Molekularbiologe, der vom Mathematiker zum Softwareentwickler wurde. Er ist ein leidenschaftlicher Open-Source-Mitarbeiter mit einem besonderen Interesse an Open Science und Publishing-Workflows und arbeitet als Core Developer für den universellen Dokumentenkonverter “pandoc”. Nachdem er seine Zeit in Lübeck, Hamburg und Menlo Park verbracht hat, lebt Albert jetzt mit seiner Frau und seinen Kindern in Berlin. Er ist auch auf GitHub and Twitter zu finden.
Porträt: Albert Krewinkel©
Felicitas Kruschick promoviert an der Leibniz Universität Hannover über Inklusive Bildung im ländlichen Ghana. Sie arbeitet am Institut für Sonderpädagogik und beschäftigt sich mit dem Konzept der Inklusiven Bildung unter der Perspektive von Machtdynamiken. Außerdem arbeitet sie an einer digitalen Lernumgebung zum Thema Inklusive Bildung und ist Stipendiatin im Open-Science-Fellow-Programm von Wikimedia. Sie ist auch auf ResearchGate und Twitter zu finden.
Porträt: Felicitas Kruschick©, CC BY-SA 4.0
Dr. Thomas Lösch arbeitet als Senior Researcher am DIPF | Leibniz-Institut für Bildungsforschung und Bildungsinformation. Im Rahmen des Verbunds Forschungsdaten Bildung (VerbundFDB) unterstützt er Bildungsforscher:innen in allen Fragen rund um das Management und die gemeinsame Nutzung von Forschungsdaten. Teil seiner Arbeit ist auch die Meta-Forschung zu Open Science in der Bildung. Er ist auch auf ORCID und Twitter zu finden.
Porträt: Thomas Lösch©
Isabella Meinecke leitet die Abteilung Elektronisches Publizieren und den Open-Access-Verlag Hamburg University Press an der Staats- und Universitätsbibliothek Hamburg sowie die Open-Access-Stelle der Bibliothek. Als Open-Access-Beauftragte der Bibliothek ist sie seit vielen Jahren in entsprechende Netzwerke und Aktivitäten eingebunden.
Dr. Guido Scherp ist Leiter der Abteilung “Open-Science-Transfer“ der ZBW – Leibniz-Informationszentrum Wirtschaft und Koordinator des Leibniz-Forschungsverbunds Open Science. er ist auch auf LinkedIn und Twitter zu finden.
Porträt: ZBW©, Fotograf: Sven Wied
Dr. Stefan Skupien arbeitet als wissenschaftlicher Koordinator für Open Science für die neu gegründete Berlin University Alliance. Zu seinen Aufgaben gehört die systematische Erhebung von empirischen Studien zur Praxis von Open Science im Rahmen einer interdisziplinären Forschungsgruppe. Als ehemaliger Stipendiat des Open Science Fellows Program beendet Stefan derzeit ein Open Data Funding Observatory für afrikanische Forscher:innen.
Porträt: Stefan Skupien©, Fotograf Ralf Rebmann, CC BY-SA 4.0
Antonella Succurro ist wissenschaftliche Mitarbeiterin und Postdoktorandin am West German Genome Center in Bonn. Sie ist Mitglied der Organisation Science for Democracy zur Förderung des Rechts auf Wissenschaft, wo sie sich auf Open Science, Diversität und Inklusion, systemische Verzerrungen (systemic bias) im Bereich der künstlichen Intelligenz konzentriert. Sie ist auch auf LinkedIn, ResearchGate und Twitter zu finden.
Porträt: Antonella Succurro©
Klaus Thoden arbeitet derzeit für die GWDG Gesellschaft für wissenschaftliche Datenverarbeitung mbH Göttingen in einem Kooperationsprojekt mit dem Max-Planck-Institut für Wissenschaftsgeschichte. Seit 2015 ist er der technische Leiter für die Edition Open Access Publication Infrastructure. Ziel der Zusammenarbeit ist es, die Textkonvertierungswerkzeuge und die Publikationsplattform bei der GWDG zu implementieren, um diese Dienste breit verfügbar zu machen.
Michela Vignoli ist Community-Koordinatorin bei Open Knowledge Maps und Forscherin am AIT Austrian Institute of Technology. Ihr Interessensschwerpunkt liegt auf Wissensmanagement im digitalen Zeitalter und auf der Frage, wie man einen systemischen Wandel hin zu Open Science umsetzen und unterstützen kann. Er ist auch auf Twitter zu finden.
Porträt: Michela Vignoli©
#bookliberationist Simon Worthington forscht am Open Science Lab an der TIB – Leibniz-Informationszentrum Technik und Naturwissenschaften und Universitätsbibliothek. Er ist Autor von ‘The Book Liberation Manifesto’, das Pläne für die Automatisierung von Publikationsinfrastrukturen skizziert, um dazu beizutragen, Forschung für alle zugänglich zu machen, und Herausgeber des offenen Forschungsblogs “Generation Research”.
Dr. Philipp Zumstein leitet das Team für Publikationsservices und Forschungsunterstützung an der Universitätsbibliothek Mannheim. Er ist der Open-Access-Beauftragte der Universität Mannheim, wo gerade ein Open-Science-Büro eingerichtet wurde. Er ist auch auf GitHub, ORCID und Twitter zu finden.
Porträt: Philipp Zumstein©


Open Access goes Barcamp, Teil 2: Wie man Vernetzung online gestalten kann

Art of Hosting: Betriebssystem für Open Science und Citizen Science?

Open-Access-Tage 2018 – Teil I: Wie entwickelt sich Open Access im Kontext von Open Science?
View Comments

Wissenschaftliche Tweets: Warum weniger mehr ist und wann ein Tweet als wissenschaftlich wahrgenommen wird
Twitter ist als Kommunikationskanal aus der wissenschaftlichen Community nicht mehr...