
KI in wissenschaftlichen Bibliotheken, Teil 2: Spannende Projekte, die Zukunft von Chatbots und Diskriminierung durch KI
Was sind aktuell die spannendsten KI-Projekte in Bibliotheken und Infrastruktureinrichtungen? Warum sind Chatbots als Einsatzgebiet von künstlicher Intelligenz so erfolgversprechend? Wie lässt sich verhindern, dass KI-basierte Systeme diskriminierende Entscheidungen treffen? Ist das im Bibliothekskontext überhaupt relevant? Diesen Fragen widmet sich der zweite Teil der dreiteiligen Interviewserie mit Argie Kasprzik und Frank Seeliger.
Interview mit Frank Seeliger (TH Wildau) und Argie Kasprzik (ZBW)

Kürzlich haben wir mit Argie Kasprzik (ZBW) und Frank Seeliger (TH Wildau) intensiv über den Einsatz von künstlicher Intelligenz in wissenschaftlichen Bibliotheken gesprochen. Die beiden waren unlängst an zwei ausführlichen Artikeln dazu beteiligt: “Zum erfolgversprechenden Einsatz von KI in Bibliotheken: Diskussionsstand eines White Papers in progress – Teil 1” und “Teil 2”
Dr. Argie Kasprzik leitet die Automatisierung der Sacherschließung (AutoSE) in der ZBW – Leibniz-Informationszentrum Wirtschaft. Dr. Frank Seeliger leitet die Hochschulbibliothek der Technischen Hochschule Wildau und ist mitverantwortlich für den berufsbegleitenden Masterstudiengang Bibliotheksinformatik am Wildauer An-Institut WIT (Wildau Institute of Technology).
Aus unserem mündlichen Interview ist diese leicht gekürzte, dreiteilige Serie hervorgegangen. Neben dem folgenden Text gehören diese beiden Artikel dazu:
- Teil 1: Handlungsfelder, große Player und die Automatisierung der Erschließung
- Teil 3: Voraussetzungen und Bedingungen für den erfolgreichen Einsatz
Sobald die Beiträge erschienen sind, teilen wir den Link an dieser Stelle.
Was sind aktuell die spannendsten KI-Projekte in Bibliotheken und Infrastruktureinrichtungen?
Argie Kasprzik: Natürlich gibt es gerade viele interessante KI-Projekte, spontan fallen mir diese zwei ein: Zum einen, wenn man sich mit optischer Zeichenerkennung (OCR, Optical Character Recognition) befasst – bevor man überhaupt in die automatisierte inhaltliche Erschließung einsteigen kann, muss man erst einmal Metadaten erzeugen, sozusagen als Futter; digitale Texte in ihre Strukturfragmente zerlegen, einen Abstract automatisiert rausziehen. Um das tun zu können, lässt man den eingescannten Text durch OCR laufen. Da gibt es ein interessantes Projekt: Qurator, in dem auch Machine-Learning-Methoden verwendet werden. Da sind unter anderem die Stabi Berlin und das Deutsche Forschungszentrum für Künstliche Intelligenz (DFKI) involviert. Das ist interessant, weil es uns möglicherweise irgendwann mal die Werkzeuge liefert, die wir brauchen, um überhaupt der automatisierten Inhaltserschließung den benötigten Dateninput zuliefern zu können.
Bei dem anderen Projekt handelt es sich um den Open Research Knowledge Graph (ORKG) der TIB Hannover. Der Open Research Knowledge Graph ist ein Ansatz, wissenschaftliche Ergebnisse nicht mehr als Dokument darzustellen, also als PDF, sondern entitätenbasiert. Autor:in, Forschungsthema oder Methode – alles Knoten in einem Graphen. Das ist die semantische Ebene, und um den zu befüllen, könnte man Machine-Learning-Methoden einsetzen.
Frank Seeliger: Nur ein Projekt: Das läuft an der ZBW und an der TH Wildau und befasst sich mit dem Aufbau eines Chatbots mit neuen Technologien. Von der Idee her sind Chatbots schon relativ alt. Dabei führt eine Maschine mit einem Menschen einen Dialog. Im besten Fall erkennt der Mensch nicht, dass eine Maschine im Hintergrund läuft – der Turing Test. Soweit ist man nicht, aber die Frage, die wir alle haben, ist, dass Bibliotheken konsultiert werden, zum Beispiel in Chaträumen. Der Anspruch vieler Bibliotheken ist, einen hohen Service zu den Arbeitszeiten von Forschenden und Studierenden, also rund um die Uhr, anzubieten. Das kann nur automatisiert erfolgen, eben beispielsweise über Chatbots, sodass man auch schwierige Fragen außerhalb der Öffnungszeiten, am Wochenende, feiertags beantworten kann.
Da erhoffe ich mir zum einen diesen Input, was die Chatbot-Entwicklung betrifft, sodass sie zu einem hochwertigen Standardangebot werden, das schnell Orientierung bietet und zu einer Bibliothek oder zu speziellen Dienstleistungen eine Auskunft mit einer sehr guten Aussagequalität liefert. Damit wäre die Ausgangsbasis geschaffen, um weitere Maschinen wie fahrende Roboter zu bespielen. Viele investieren in Roboter, spielen damit rum und machen verschiedene Versuche. Aber wenn die Erwartungshaltung ist, hinzugehen und zu fragen, „Wo ist das Buch XY?“ oder „Wie finde ich das und das?“ und dass diese Roboter mit solchen Fragen gewinnbringend umgehen können und orientiert zeigen „Da ist das“ und mit dem Finger darauf zeigen. Das ist das eine.
Das zweite, was ich projektbezogen sehr spannend finde, ist, die Leute frühzeitig mit KI mitzunehmen. Das nicht nur als Buzzword abzuspeichern, sondern dass hinter die Kulissen geschaut wird. Wir haben versucht, einen Zertifikatskurs anzubieten. Bisher ist er aber wegen zu geringer Nachfrage nicht zustandegekommen. Aber wir versuchen es weiter. Von der Nationalbibliothek gibt es so einen Kurs, der gut besucht wurde. Wichtig finde ich, dass man spartenübergreifend ein niedrigschwelliges Angebot macht, also für eine One Person Library oder für kleine städtische Bibliotheken, die kommunal aufgestellt sind, genauso wie für größere Hochschulbibliotheken. Dass sich die Menschen mit der Materie auseinandersetzen und ihren Weg finden, den sie gehen können, wo sie etwas nachnutzen können, wo es Anbieter:innen gibt oder Kooperationspartner:innen. Das ist ein Projekt, was ich sehr interessant und sehr wichtig für die Bibliothekswelt finde.
Aber auch das kann nur ein Auftakt sein von vielen anderen Angeboten zu speziellen Workshops, meinetwegen zu Annif oder zu anderen Themen, bei denen man sich auf einer Ebene austauscht, die auch Nicht-Informatiker:innen verstehen. Ein Angebot an Kolleg:innen, die sich damit beschäftigen, aber nicht unbedingt in der Tiefe. Wie beim Auto – sie stellen es nicht selbst her, aber möchten es mal reparieren oder tunen können. Auf dieser Ebene brauchen wir unbedingt mehr Austausch mit den Menschen, die damit arbeiten müssen, beispielsweise als Systemadministrator:innen, die solche Projekte aufsetzen oder leiten. Aber die Angebote müssen sich auch an die Leitungsebene, die eine Budgetierung vornimmt, also Drittmittel-Anträge unterzeichnet, richten.
An beiden Institutionen, an denen ihr arbeitet (ZBW und TH Wildau), wird am Einsatz von Chatbots gearbeitet. Warum ist dieses KI-Einsatzgebiet für wissenschaftliche Bibliotheken erfolgversprechend? Was sind aktuell die größten Herausforderungen?
Frank Seeliger: Die interessante Perspektive für mich ist, dass man den Aufbau eines Chatbots gemeinsam mit anderen Bibliotheken betreiben kann. Schön ist es ja, wenn die typischen Beispiele nicht nur aus einer Bibliothek als Knowledge Base im Hintergrund laufen. Das geht nicht bei lokal spezifischen Informationen wie Öffnungszeiten oder zu den räumlichen Gegebenheiten. Trotzdem entstehen viele Synergieeffekte. Wenn wir die zusammenbringen können und darüber in der Lage sind, eine so große Datenmenge zu generieren, dass die Aussagequalität, die automatisiert produziert wird, einfach besser ist, als wenn man das alleine aufsetzt. Die Output-Qualität hängt ja mit der Datenmenge zusammen. Auch wenn nicht gilt: Je mehr Daten, desto besser die Auskunft. Da spielen noch andere Faktoren eine Rolle. Doch in der Regel scheitern kleine Lösungen daran, dass die Datenmenge sehr überschaubar ist.
Vor allem im Hinblick darauf, dass relativ viele Bibliotheken Lust haben, in Roboter-Lösungen zu investieren, die außerhalb der Öffnungszeiten durch die Bibliothek „laufen“ und Dienste anbieten, wie der Robot Librarian. Dadurch macht es im Anwendungsfall doppelt Sinn, online etwas anzubieten, aber das auch auf eine Maschine zu apportieren, die durch die Räumlichkeiten rollt und den Service anbietet. Das ist wichtig, weil die persönliche Ansprache aus der Bibliothek an die Kund:innen ein sehr entscheidendes und unterscheidendes Merkmal im Gegensatz zu großen Metaebenen ist, die im kommerziellen Bereich ihre Dienste anbieten. Den Dialog zu suchen, auf die speziellen Bedürfnisse der Nutzer:innen einzugehen, das macht den Unterschied.
Argie Kasprzik: Auch wenn ich bei dem Chatbot-Projekt der ZBW nicht beteiligt bin, fallen mir drei Herausforderungen ein. Die erste ist, dass man irre viele Trainingsdaten braucht. Die zu bekommen, ist relativ schwer. Hier an der ZBW gibt es ja schon länger einen Chat – ohne Bot. Diese Chats wurden mitgeschnitten, mussten dann aber erst mal von allen persönlichen Daten bereinigt werden. Und das ist eine immense Aufbereitungsarbeit. Das ist die erste Herausforderung.
Die zweite: Es ist so, dass relativ triviale Fragen leicht zu beantworten sind, wie die nach den Öffnungszeiten. Aber sobald es komplex wird, wenn es also um fachliche Fragen geht, bräuchte man eigentlich erst mal einen Wissensgraphen hinter dem Chatbot. Und den zu erstellen, ist schon relativ komplex.
Und damit kommen wir zur dritten Herausforderung: Das Projektteam hat in den ersten Läufen festgestellt, dass unter den Nutzer:innen relativ viele Leute Vorbehalte haben und schnell sagen „Der versteht mich nicht“. Auf beiden Seiten gibt es also Vorbehalte. Wir müssen uns also noch annähern, sowohl in der Qualität als auch in der „Zutraulichkeit“ der Nutzenden.
Frank Seeliger: Aber die Interaktionen gehen auch in Richtung des Sprechens, gerade von der Generation, die nachwächst, die jetzt als Studierende in die Bibliotheken kommt. Die Generation kommuniziert über Sprachnachrichten, sie spricht mit Siri oder Alexa und duzt sich mit den Technologien. In Karlsruhe gab es Versuche mit Alexa, Suchanfragen zu definieren. Das lief an sich gut, aber es scheiterte an der Datenschutz-Grundverordnung (DSGVO), der Privatheit der Informationen und der Verarbeitung von Daten irgendwo in den USA. Das geht natürlich nicht.
Deswegen ist es gut, dass Bibliotheken etwas Eigenes machen, weil sie dann die Datenhoheit haben und dafür sorgen können, dass die DSGVO eingehalten und sorgsam mit den Daten der Nutzenden umgegangen wird. Aber sich überhaupt nicht mit dem entsprechenden Dialog darauf einzustellen, wäre strategisch ein Fehler für Bibliotheken. Ganz einfach, weil sehr viel in diesen Interaktionen nicht mehr nur mit Schreiben und Lesen, sondern mittels Sprechen stattfindet. Bei Apps und Features findet sehr viel über Sprachnachrichten statt, und darauf müssen Bibliotheken sich einstellen.
Das fängt mit Chatbots an, aber die Frage ist, ob Suchmaschinen irgendwann mit (Sprach-)Nachrichten umgehen können und dann rausfiltern, was die eigentliche Frage ist. Einen Chatbot funktionsfähig und alltagstauglich zu machen, ist nur der erste Schritt. Mit der gesprochenen Sprache kommt das Hören und Verstehen hinzu.
Gibt es einen Zeithorizont für die Entwicklung des Chatbots?
Argie Kasprzik: Wann die ZBW vorhat, ihren Chatbot online zu stellen, weiß ich nicht genau, das kann ein, zwei Jahre dauern. Die eigentliche Frage ist, wann wird das bibliotheksglobal eine tragfähige Lösung sein. Das kann noch mindestens zehn Jahre oder länger dauern – ohne die Hoffnung zu sehr zerschlagen zu wollen.
Frank Seeliger: Es gibt immer wieder unvorhergesehene Revivals, für die es gewisse Impulse braucht. Ich war zum Beispiel in der IT-Sektion der International Federation of Library Associations and Institutions (IFLA) zur Statistik. Wir haben überlegt, ob wir klar und global Statistiken eruieren und als Mappe darstellen können. Das ging erstmal nicht, war kapriziert auf einen Kontinent – Lateinamerika. Dann bekam die Sektion überraschend von der Melinda and Bill Gates Foundation wahnsinnig viel Geld. Damit konnte man das Projekt Librarymap umsetzen.
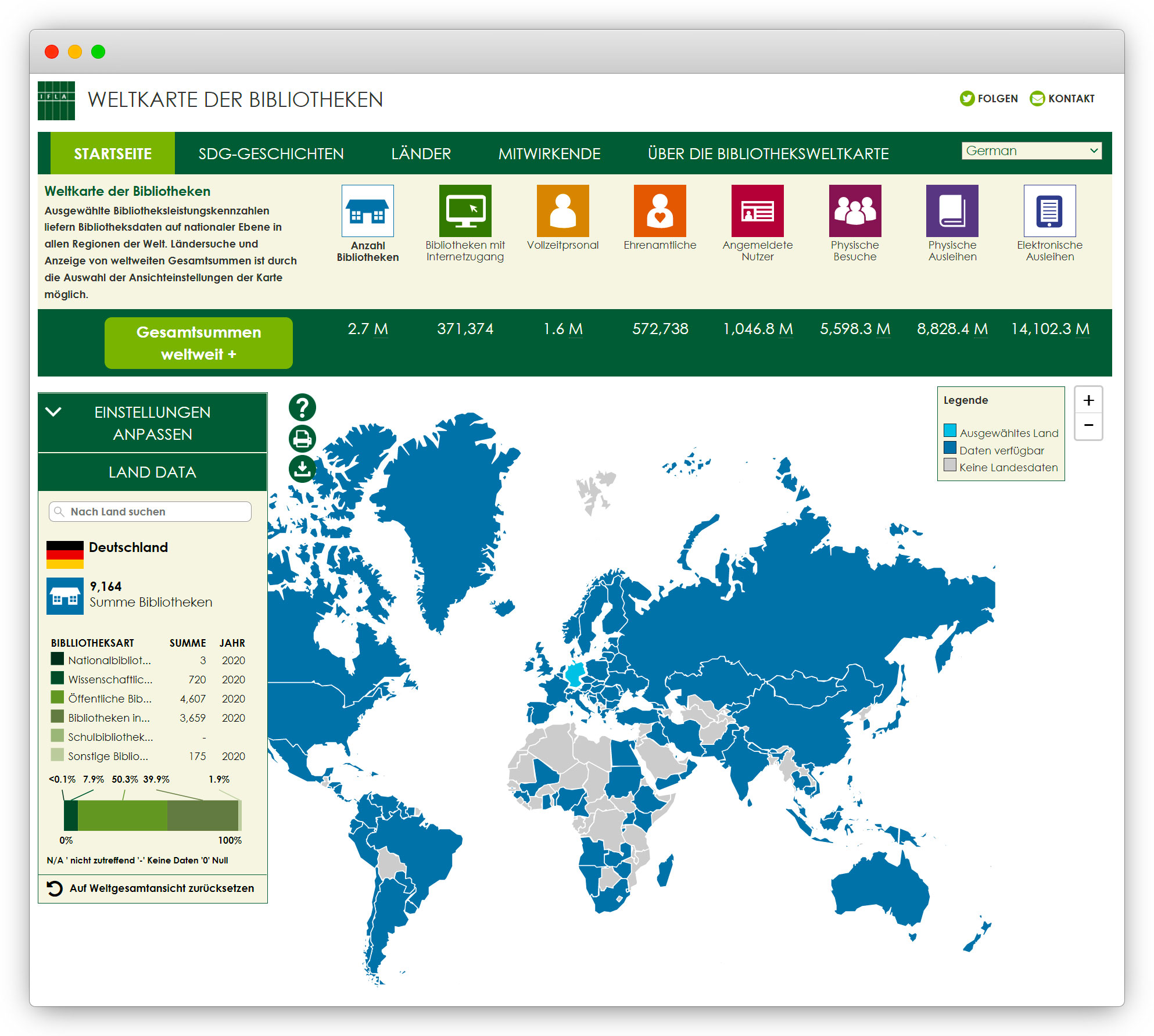
Es war also ein ganz spezieller Impuls, der zu etwas geführt hat, was wir mit den normalen Voraussetzungen wahrscheinlich in zehn Jahren Arbeit nicht geschafft hätten. Und wenn es solche Impulse gibt durch Ausschreibungen, durch Mittel, über Drittmittelgeber:innen, die genau so etwas forcieren, vielleicht auch auf lange Sicht, bekommt das Ganze eine neue Dynamik. Wenn die Entwicklung von Chatbots in Bibliotheken aber weiter so dahindümpelt, werden sie sie nicht marktdurchgreifend anwenden.
Also mit kontaktloser Objekterkennung über Radiowellen (Radio Frequency Identification, RFID) gab es auch mal eine Bewegung. 2001 fing das in Siegburg an, dann Stuttgart, München und mittlerweile hat sich das bei 2000 bis 3000 Bibliotheken durchgesetzt. Diesen Impuls sehe ich bei Chatbots gar nicht. Deswegen würde ich nicht sagen, dass in zehn, 15 Jahren 10% bis 20 % der Bibliotheken Chatbots einsetzen. Es ist ein Versuchsfeld. Vielleicht führen einige Bibliotheken sie ein, aber es wird eine Handvoll sein, vielleicht ein Dutzend. Wenn es allerdings durch externe Faktoren ein Zugpferd gibt, durch Mittel oder durch eine Netzwerkinitiative, kann das Ganze einen anderen Drive bekommen.
Dass KI-basierte Systeme diskriminierende Entscheidungen treffen, wird häufig als generelles Problem gesehen. Gilt das auch für den Bibliothekskontext? Wie kann man das verhindern?
Argie Kasprzik: Das ist eine sehr schwierige Frage. Eine relativ bekannte Wahrheit ist, dass potenzielle Schieflagen fast immer aus den Trainingsdaten kommen, denn die Trainingsdaten sind menschliche Daten. Unsere Vorurteile stecken in diesen Daten. Es kommt also auf die Daten an sich an und auf die Wissensorganisationssysteme, die dahinterliegen. Von diesen beiden Faktoren hängt ab, ob die Ergebnisse diskriminierend wirken können oder nicht.
Eine Sache, die zumindest gerade Fahrt aufnimmt, nennt sich Dekolonialisierung. Man wirft also gerade auf dieses Vokabular, Thesauri und Ontologien einen Blick. Das Problem ist bei uns auch schon hochgekommen: Weil wir historische Texte erfasst haben, kamen auch Begriffe im Thesaurus vor, die heutzutage rassistisch konnotiert sind. Natürlich verzeichnen wir hauptsächlich die Begriffe, die als politisch korrekt gelten. Das verschiebt sich aber auch immer mal wieder. Die Frage ist, was macht man mit historischen Texten, wo das im Titel steht? Da gilt es, verschiedene Möglichkeiten zu finden, das im Thesaurus zu hinterlegen, es aber an der Oberfläche nicht anzuzeigen.
Es gibt Wissensorganisationssysteme, die sehr alt und in anderen Zeiten entstanden sind. Die müssen wir dringend komplett umstrukturieren. Möchte man Texte von früher mit den Strukturen, die damals gedacht wurden, darstellen, ist das immer eine Gratwanderung. Denn ich darf sowohl den historischen Kontext nicht verfälschen, aber auch niemanden vor den Kopf stoßen, der:die in diesen Texten suchen und sich repräsentiert oder zumindest nicht diskriminiert fühlen will. Das ist eine sehr schwierige Frage, auch und gerade in Bibliotheken. Man denkt ja oft: Das ist doch keine Frage für Bibliotheken, das ist doch Politik oder so. Aber im Gegenteil, Bibliotheken sind am Puls der Zeit und müssen es sein.
Frank Seeliger: Alles, was man gebrauchen kann, kann man auch missbrauchen. Das gilt für jedes Objekt. Ich war zum Beispiel so beeindruckt in der Türkei. Die arbeiten mit einem großen Koha-Ansatz (Bibliothekssoftware), d.h. über 1000 öffentliche Bibliotheken verwenden als Bibliotheksmanagementsystem die Open-Source-Lösung Koha. Dadurch wissen sie unter anderem, welches Buch in der Türkei am häufigsten ausgeliehen wurde. Solche Informationen haben wir in Deutschland über die Deutsche Bibliotheksstatistik (DBS) gar nicht. Das heißt nicht, dass man mit diesem Wissen die anderen Bücher diskreditiert, dass sie automatisch Ladenhüter sind. Man kann mit Wissen sehr viel anfangen. Der Bias, den es bei KI gibt, ist sicherlich der bekannteste. Aber es ist bei allen Informationen so: Stürzt man Denkmäler oder lässt man sie? Da gilt es, in den verschiedenen moralischen Phasen, die man als Gesellschaft durchlebt, einen Weg zu finden.
Ich habe Alt-Amerikanistik studiert. Die Azteken haben sich zum Beispiel nie Azteken genannt. Wenn man in Katalogen von Bibliotheken vor 1763 gesucht hat, gab es den Begriff „Azteken“ nicht. Sie haben sich selber Mexi‘ca genannt. Oder nehmen wir die Kerenskj-Offensive, bei der Suchmaschinen schwach sind. Das war eine Militäroffensive, die erst im Nachgang so benannt wurde. Die hieß vorher anders. Das ist die gleiche Herausforderung, aufeinander zu verweisen, auch wenn sich die Begrifflichkeiten geändert haben oder wenn es nicht mehr „en vogue“ ist, mit einem bestimmten Begriff zu arbeiten.
Argie Kasprzik: Man spricht auch von Concept Drift. Das ist generell ein großes Problem. Deswegen muss man die Maschinen immer nachtrainieren: Konzepte entwickeln sich weiter, neue tauchen auf oder alte Terme verändern ihre Bedeutung. Selbst wenn es nicht diskriminiert, bewegt sich die Historie immer weiter.
Und wer macht das?
Argie Kasprzik: Die Machine-Learning-Expert:innen an der Einrichtung.
Frank Seeliger: Der jeweilige Zeitgeist und die dafür vorgesehene Struktur.
Vielen Dank für das Gespräch, Argie und Frank.
In Teil 1 des Interviews zu „KI in wissenschaftlichen Bibliotheken“ geht es um Handlungsfelder, große Player und die Automatisierung der Erschließung.
In Teil 3 des Interviews zu „KI in wissenschaftlichen Bibliotheken“ geht es um: Voraussetzungen und Bedingungen für den erfolgreichen Einsatz.
Das könnte Sie auch interessieren:
- Zum erfolgversprechenden Einsatz von KI in Bibliotheken : Diskussionsstand eines White Papers in progress – Teil 1 und Teil 2
- Aufbau eines produktiven Dienstes für die automatisierte Inhaltserschließung an der ZBW – ein Status- und Erfahrungsbericht, Vortragsfolien vom Bibliothekskongress in Leipzig
- Automating subject indexing at ZBW – the costs of the digital transformation and why we need less projects, Vortragsfolien LIBER 2022
- 14. Wildauer Bibliothekssymposium am 13. & 14. September 2022, inklusive “Best of Scheitern”
- Zum Arbeitsschwerpunkt „Automatisierung der Erschließung mit Methoden der Künstlichen Intelligenz“ der ZBW
- Diskriminierung durch KI: Inwiefern Bibliotheken betroffen sind und wie Mitarbeitende das richtige Mindset finden
- Bibliotheken: Bücherspeicher und Datenwolken
- Künstliche Intelligenz: Neue Perspektiven für Citizen Science, Forschung und Bibliotheken
- Science Checker: Behauptungen mit Open Access und künstlicher Intelligenz prüfen
- Digitale Open-Science-Tools: mehr Offenheit durch inklusives Design
- Horizont-Bericht 2020: AI, XR und OER setzen sich langsam in der Hochschulbildung durch
- DGI-Praxistage: Wie verändert künstliche Intelligenz die Arbeitswelt von Information Professionals?
- Hackathon Coding.Waterkant: Wie man Bibliotheksservices durch Chatbots und künstliche Intelligenz besser machen kann
- Revival der Chatbots: Revolution des Kundenkontakts, Disruption des Software-Marktes?
- Google engineer put on leave after saying AI chatbot has become sentient
Dr. Argie Kasprzik leitet die Automatisierung der Sacherschließung (AutoSE) in der ZBW – Leibniz-Informationszentrum Wirtschaft. Argies Arbeitsschwerpunkt liegt auf der Überführung aktueller Forschungsergebnisse aus den Bereichen Machine Learning, semantische Technologien, Semantic Web und Wissensgraphen in den Produktivbetrieb der Sacherschließung der ZBW. Sie ist auch auf Mastodon zu finden.
Porträt: ZBW©, Fotografin: Carola Gruebner
Dr. Frank Seeliger leitet die Hochschulbibliothek der Technischen Hochschule Wildau seit 2006 und ist seit 2015 mitverantwortlich für den berufsbegleitenden Masterstudiengang Bibliotheksinformatik am Wildauer An-Institut WIT (Wildau Institute of Technology). Ein Modul befasst sich dabei mit KI. Er ist auch auf ORCID zu finden.
Porträt: TH Wildau
Featured Image: Alina Constantin / Better Images of AI / Handmade A.I / Licensed by CC-BY 4.0


Coding da Vinci 2018: Hackathon mit Open Data aus Forschung und Kultur

Digitale Weiterbildung: Ein Leben lang lernen?

Bibliothek als Ort nach Corona: Hybrid und partizipativ?
View Comments
KI in wissenschaftlichen Bibliotheken, Teil 1: Handlungsfelder, große Player und die Automatisierung der Erschließung
Was sind die erfolgversprechendsten Handlungsfelder für den Einsatz von künstlicher...