
Science 2.0 Research Project MOVING: Big Data Analyses for Non-Computer Scientists
Given the constraints of information overload and limited time resources, how can you find information relevant to finishing information-intensive tasks? Computer science provides methods for this, but usually only experts know how to use them. The EU project MOVING aims to empower ordinary users by providing a platform and training for such methods.
In April, the ZBW and eight international partners from Greece, Germany, Austria, Slovenia, Great Britain and Poland have started the large-scale EU project “MOVING – Training towards a society of data-savvy information professionals to enable open leadership innovation”. The ZBW is the research partner for text and data mining under the direction of Prof. Dr. Ansgar Scherp, who is also the scientific coordinator of MOVING. MOVING is the second international research project initiated by the ZBW which addresses Science 2.0 in the context of Horizon 2020, after the EU project EEXCESS.
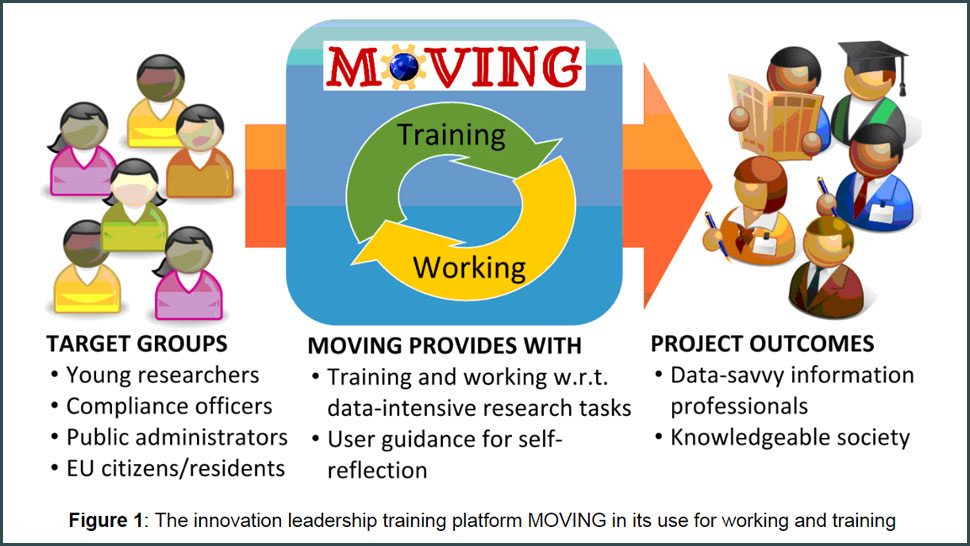
MOVING’s objective is to establish a working and training platform for the qualitative and quantitative analysis of big document and data collections in order to meet the rapidly growing amount of published research documents and data collections. This constitutes a challenge for researchers as well as for innovation managers, who need to sift quickly a wide range of available information to find what is relevant to them.
Prof. Dr. Ansgar Scherp illustrates the project details for us. He is the project’s research coordinator and professor for Knowledge Discovery at the ZBW and the University of Kiel.
In MOVING you are developing a working and training environment for digital information and innovation management. At the same time your goal is to foster the skills of the platform users, for instance researchers, in digital information and innovation management. How do you plan to accomplish that goal?
The development, application and hands-on testing of novel approaches in semantic information retrieval and management in MOVING is not limited to research publications, for instance from the ZBW, but looks in particular at websites, social media and video content from other project partners. In order to support the users in their information retrieval and management, we will analyze their interactions. For example: What search queries do they enter, what is the chronological order in which they use the range of functions available on the platform, such as search, visualization und organization, and how do the users communicate among each other. We will process and interpret this information in the background using a didactical model. Finally, we will apply the insights we gain for recommendations and to enhance the information retrieval and management.
So, with MOVING you will make methods from computer sciences for the handling of abundant document and data amounts available to laypersons, who would otherwise be unable to apply them. On what content will you use those methods and which subjects do you cover?
We focus on two use cases in MOVING: First a use case of Ernst & Young Wirtschaftsprüfer GmbH which is about the continuous training and further education of their employees. The second use case centers on “young researchers” like PhD candidates and graduate students. This use case is covered by TU Dresden. As content we use published sources and data like websites and videos, but also social media. We also make special use of the ZBW’s content, for example open access publications in economics and business studies
To what extent will you embrace user feedback?
The development of the MOVING platform is human-centered and applies correspondent qualitative and quantitative methods. This means that the different stakeholders from the two use cases of the project mentioned above will participate in the development and the evaluation of the MOVING platform from the beginning.
How could the results or findings of the MOVING project be interesting for future library services?
The findings derived from the project could help to create new value added services and novel discovery systems for libraries. This is of special interest, as users find it more and more difficult to navigate their way around huge amounts of documents and scholarly publications. Classical search systems reach their limits here and it is necessary to try new ways and methods.
The ZBW is the leading research partner and responsible for text and data mining. What exactly do you and your research team do?
In the project, the Knowledge Disovery group is mainly active in the analysis of unstructured textual contents and the search for these contents. In doing so, we do not only use the newest research methods, but also explore new methods to enhance the search. In this process we combine established statistical models of information retrieval with semantic features in order to create a new kind of access to the ZBW’s contents. In the EU project MOVING, we are in charge of the work package “Data processing and data visualization technology”. Our first results show for instance that it is possible to recommend research literature or to categorize documents by analyzing title data only. The advantage of this is that the legal framework of text and data mining no longer constitutes a hurdle and we can offer a service of similar quality with much less computing time.
Which outstanding challenges do you expect?
One of MOVING’s key characteristics is its interdisciplinarity. Didacts, media experts and computer scientists work together to develop new forms of retrieval and organization of information, documents, data and so on. Our Knowledge Discovery group is used to this kind of challenges and already meets them successfully in our interdisciplinary ZBW project AutoIndex, where we explore techniques and applications for the semi-automatic indexing of full texts
What facet of your project are you personally especially curious about?
MOVING’s slogan is “Bringing Structure to the Unstructured”. Or, to put it another way, we want to equip people with the skills necessary for using digital tools in information retrieval and management. We also want to empower them to use and apply digital contents as naturally and confidently as they do today with long-established techniques such as reading and writing literature.
→ Author: Prof. Dr. Ansgar Scherp (Head of the Knowledge Discovery Group at ZBW and Professor for Knowledge Discovery, Kiel University)


Open Science Podcasts: 7 + 3 Tips for Your Ears

Impact School 2017: Academic Impact Outside of Academia

Further Training Market for Future Skills: Start-ups Provide Practical Orientation and Inspiration
View Comments

Building Communities of Librarians and Information Specialists in Business and Economics
von Tamara Pianos, Andrea Schlotfeldt, Olaf Siegert und Karin Wortmann The INCONECSS...