
Machine Learning: So wird die Sacherschließung automatisiert
Machine-Learning-Methoden ermöglichen große Fortschritte bei der Automatisierung der Sacherschließung. Welche Herausforderungen es dabei gibt und wie weit die Integration in den Regelbetrieb fortgeschritten ist, schildert Dr. Argie Kasprzik im Interview.
im Interview mit Argie Kasprzik
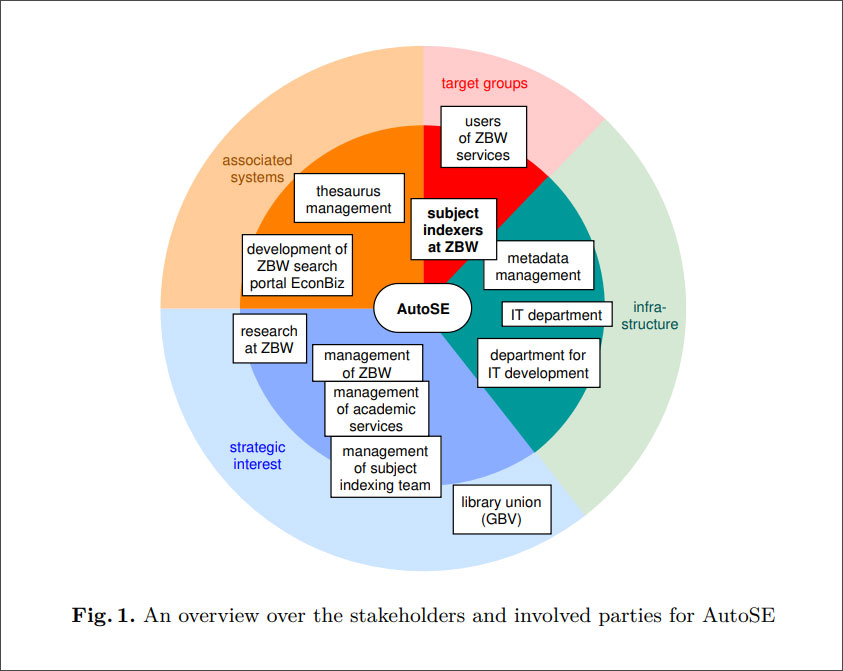
 Die Sacherschließung in Bibliotheken ist nach wie vor aufwändig. Machine-Learning-Methoden bieten das Potenzial für Erleichterungen bei der Arbeit. Wir haben mit Dr. Argie Kasprzik über die Automatisierung der Sacherschließung gesprochen. Sie ist seit Ende 2018 wissenschaftliche Mitarbeiterin an der ZBW – Leibniz-Informationszentrum Wirtschaft und hat die Leitung / Koordination der Automatisierung der Sacherschließung mit Machine-Learning-Methoden (AutoSE) inne.
Die Sacherschließung in Bibliotheken ist nach wie vor aufwändig. Machine-Learning-Methoden bieten das Potenzial für Erleichterungen bei der Arbeit. Wir haben mit Dr. Argie Kasprzik über die Automatisierung der Sacherschließung gesprochen. Sie ist seit Ende 2018 wissenschaftliche Mitarbeiterin an der ZBW – Leibniz-Informationszentrum Wirtschaft und hat die Leitung / Koordination der Automatisierung der Sacherschließung mit Machine-Learning-Methoden (AutoSE) inne.
Angetreten ist sie mit dem Auftrag, Brücken zwischen Forschung und Bibliotheksbetrieb zu schaffen und den Transfer von Forschungsergebnissen in die Praxis zu sichern.
Wie setzt ihr Machine Learning für die automatische Sacherschließung in der ZBW ein?
Beim Machine Learning braucht man zunächst immer Trainingsdaten, damit die Maschine ein Vorbild hat, von dem sie lernen kann. Trainingsdaten sind in unserem Fall Metadatensätze zu Ressourcen, die intellektuell mit dem Standard-Thesaurus Wirtschaft (STW) erschlossen worden sind. Mit diesen werden dann mehrere Machine-Learning-Verfahren trainiert und deren Ergebnisse in einem regelbasierten Fusion-Ansatz verbunden: Ein STW-Deskriptor muss von mindestens zwei Verfahren vorgeschlagen werden, sonst wird er nicht aufgenommen; und für eine Ressource müssen mindestens zwei STW-Deskriptoren aus den STW-Subthesauri für BWL oder VWL vorgeschlagen werden.
Welche Erfahrungen habt ihr dabei bisher gesammelt?
Erste Schritte mit Machine-Learning-Methoden zu gehen ist einfach – diese Machine-Learning-Methoden dann aber auch auf einen Stand zu bekommen, der den Ansprüchen unseres Arbeitskontextes genügt, ist eine sehr komplexe Aufgabe. Eine grundlegende Voraussetzung ist das Vorhandensein geeigneter Trainingsdaten – das betrifft nicht nur die Menge (je mehr, desto besser), sondern insbesondere auch deren Diversität: idealerweise sollten für alle Fälle (das heißt für alle STW-Deskriptoren), die ich unterscheiden will, genügend Metadatensätze vorliegen, in denen diese Deskriptoren vorkommen, um der Maschine genügend Beispiele zu liefern, aus denen sie lernen kann, wie das gewünschte Ergebnis aussehen soll.
Wie ist der Stand bei der Automatisierung der Sacherschließung?
Im Laufe der letzten Jahre wurde in einem ZBW-internen forschungsbasierten Projekt eine machine-learning-basierte, prototypische Lösung entwickelt, mit deren Hilfe seit 2016 schon vier Abzüge der EconBiz-Metadatenbasis für den ZBW-Bestand verarbeitet und die Ergebnisse wieder in die Datenbasis eingespielt wurden. Diese Lösung ist allerdings noch nicht in die sonstigen produktiven Arbeitsabläufe des Bibliotheksbetriebs integriert; der Prozess musste bisher von Hand angestoßen werden.
Was ist die größte Herausforderung bei der Automatisierung der Sacherschließung?
Die Automatisierung der Sacherschließung ist ein Spagat zwischen den Qualitätsstandards, wie sie durch die bisherige intellektuelle Sacherschließung definiert werden, und dem technologischen Wandel, aus dem sich gegebenenfalls im Bereich des Retrievals neue Anforderungen, aber auch neue Potenziale ergeben.
Skip to PDF contentKernziel der Erschließung ist es natürlich weiterhin, Nutzerinnen und Nutzern auf eine inhaltliche Suchanfrage hin die relevantesten Ressourcen zu präsentieren, und das macht nur dann Sinn, wenn möglichst viele Ressourcen erschlossen sind, sonst sind sie nicht vergleichbar – hier kann eine Automatisierung der Sacherschließung natürlich dabei helfen, Bestände zu erschließen, die zahlenmäßig intellektuell nicht mehr zu bewältigen sind. Des Weiteren schafft eine inhaltliche Erschließung mit unserem kontrollierten Vokabular, dem STW, nur dann einen Mehrwert gegenüber modernen Text-Mining-Algorithmen, wenn wir der Ressource damit strukturierte semantische Informationen mitgeben, die im Retrieval auch ausgewertet werden können.
Durch die Verfügbarkeit externer Zusatzinformationen, etwa aus der Linked Open Data Cloud, ergeben sich in Kombination mit semantischen Technologien ganz neue Möglichkeiten. Diese müssen jedoch erst auf ihre Alltagstauglichkeit geprüft und Schritt für Schritt in Lösungen gegossen werden, die im heutigen Bibliotheksbetrieb auch umsetzbar sind.
Wie wird die automatisierte Sacherschließung von einem Projekt zu einer dauerhaften Aufgabe?
Zunächst einmal, in dem man sie offiziell zu einer Daueraufgabe erklärt, sie entsprechend priorisiert – und mit den entsprechenden Ressourcen versieht. Diesen Schritt haben wir an der ZBW bereits vollzogen und einen zusätzlichen Software-Entwickler eingestellt, der uns über die nächsten Jahre hinweg dabei helfen soll, eine Architektur aufzubauen, die die Integration von Machine-Learning-Lösungen in den Sacherschließungsbetrieb an der ZBW erlaubt. So soll sichergestellt werden, dass Ergebnisse aus der angewandten Forschung auch tatsächlich in der Praxis ankommen.
Weitere Informationen
- Vortragsfolien “Putting Research-based Machine Learning Solutions for Subject Indexing into Practice” (Folien in englischer Sprache) von Dr. Argie Kasprzik.
- Conference Paper: Kasprzik, Argie: Conference Paper — Published Version: Putting Research-based Machine Learning Solutions for Subject Indexing into Practice (PDF).
- Proceedings of the Conference on Digital Curation Technologies (Qurator 2020) (Link in englischer Sprache) vom 20.01. – 21.01.2020 in Berlin.
- Informationen zum ZBW-Projekt Automatisierung der Erschliessung mit Methoden der künstlichen Intelligenz.
Dr. Argie Kasprzik koordiniert und leitet die Automatisierung der Sacherschließung mit Machine-Learning-Methoden (AutoSE) an der ZBW – Leibniz-Informationszentrum Wirtschaft. Zuvor hat sie in Theoretischer Informatik in Trier promoviert und ein Bibliotheksreferendariat (Q4) an der Bibliotheksakademie Bayern in München mit praktischem Jahr am Kommunikations-, Informations-, Medienzentrum in Konstanz angeschlossen. Sie ist auch auf Twitter zu finden.
Porträt: ZBW©, Fotografin: Carola Gruebner

EconBiz for iPhone: ZBW launcht neue App für alle Wirtschaftswissenschaftler

Logistik-Innovationen: Mit Drohnen, Big Data und Social Delivery gegen #icanhazPDF?

Digitale Langzeitarchivierung: Die Vermessung von Netzwerken mit der nestor-Community-Umfrage
View Comments

Open-Science-Reife: Universitäten in Finnland an der Spitze
Finnland hat bei der Förderung einer Open-Science-Kultur auf nationaler Ebene bereits...