
Open Science Conference 2025: Shaping a Bright Future for Open Science and AI
This year’s Open Science Conference was dedicated entirely to Open Science and AI. Participants examined both the opportunities and the challenges at this intersection, exploring how to responsibly integrate AI into research processes and, conversely, how to build trustworthy AI on trustworthy data.
by Marie Alavi, Felix Bach, Jan Bernoth, Aysa Ekanger, Tim Errington, Vanessa Guzek, Johanna Havemann, Anna Jacyszyn, Tobias Kerzenmacher, Jochen Knaus, Firas Al Laban, Ilona Lipp, Pablo Hernández Malmierca, Katja Mayer, Katharina Miller, Anika Müller-Karabil, Nancy Nyambura, Isabel Barriuso Ortega, Guido Scherp, Stefan Skupien, Mahsa Vafaie and Nicolaus Wilder
From 8 to 9 October 2025, over 200 participants from 27 countries came together in Hamburg and online for the Open Science Conference, which this year explored the relationship between Open Science and artificial intelligence (AI). It is a highly dynamic field where there is still a great need for exchange and collaboration. That’s why the conference was designed around highly interactive formats to spark debate and develop concrete solutions. In his opening, Professor Klaus Tochtermann encouraged participants to “ask hard questions, share what works and what does not in your own research context.” Two inspiring keynotes framed the conference programme.
In his keynote “FAIR and Verifiable: The Role of FAIR Digital Objects in Trusted AI,” Dr Erik Schultes explored how FAIR data principles (Findable, Accessible, Interoperable, Reusable) and artificial intelligence can mutually reinforce each other. He emphasised that while AI systems can generate complex scientific insights, their trustworthiness depends on the quality and FAIRness of the underlying data. At Leiden University, Schultes’ team demonstrated this synergy by using the FAIR-ifying platform SENSCIENCE and its AI Clara to automatically generate an article which passed a peer review, an interactive data explorer , and podcast, solely using a Master thesis with its data. His group also applies nanopublications based on FAIR Digital Objects to produce standardised, machine-readable metadata linking datasets, methods, and publications, forming searchable institutional knowledge graphs. He also highlighted the FAIR AI Attribution (FAIA) project, which tags AI-generated content to ensure transparency. Other issues he discussed were broader, such as today’s internet being overloaded by AI-generated data. Schultes concluded that trusted AI should both consume and produce FAIR data, enabling open and verifiable science.
In her keynote “Data Infrastructures and Data Competencies as a Foundation for AI Projects”, Professor Sonja Schimmler highlighted how robust data infrastructures and data competencies form the backbone of trustworthy and transparent AI research. She emphasised that the rise of generative AI and Large Language Models requires FAIR data ecosystems to ensure reproducibility, transparency, and ethical responsibility. Through projects such as NFDI4DS, Data Competency Centers or QUADRIGA (German language) , the initiatives develop infrastructures and training programs that link AI methods with Open Data principles, knowledge graphs, and FAIR Digital Objects. Linked repositories, SPARQL endpoints, and automated metadata metrics make datasets and models findable, trustworthy, and fit for reuse. The talk underscored Open Science as a prerequisite for responsible AI – not merely as data sharing, but as a cultural shift toward collaborative, transparent, and machine-interpretable research practices based on FAIR, CARE, and TRUST principles to secure transparency, accountability, and reuse at scale.
Beyond the keynotes, participants joined discussion and solution sessions to dive deeper into specific aspects of Open Science and AI, complemented by a panel examining the role of Open Science in safeguarding the research enterprise. In this report, session contributors share their insights and key takeaways.
Opportunities and risks at the intersection of AI
and Open Research Data
by Ilona Lipp
We started the session by voting on three controversial statements. Almost 100 people took part and the majority of the audience agreed that “More research data should be shared so that better AI can be developed” (80%) and that “Preventing the potential misuse of their data in AI development is NOT the individual researcher’s responsibility” (79%). The most controversial statement (exactly 50%-50%) was “Developments in AI will lead to researchers producing higher quality research data.“
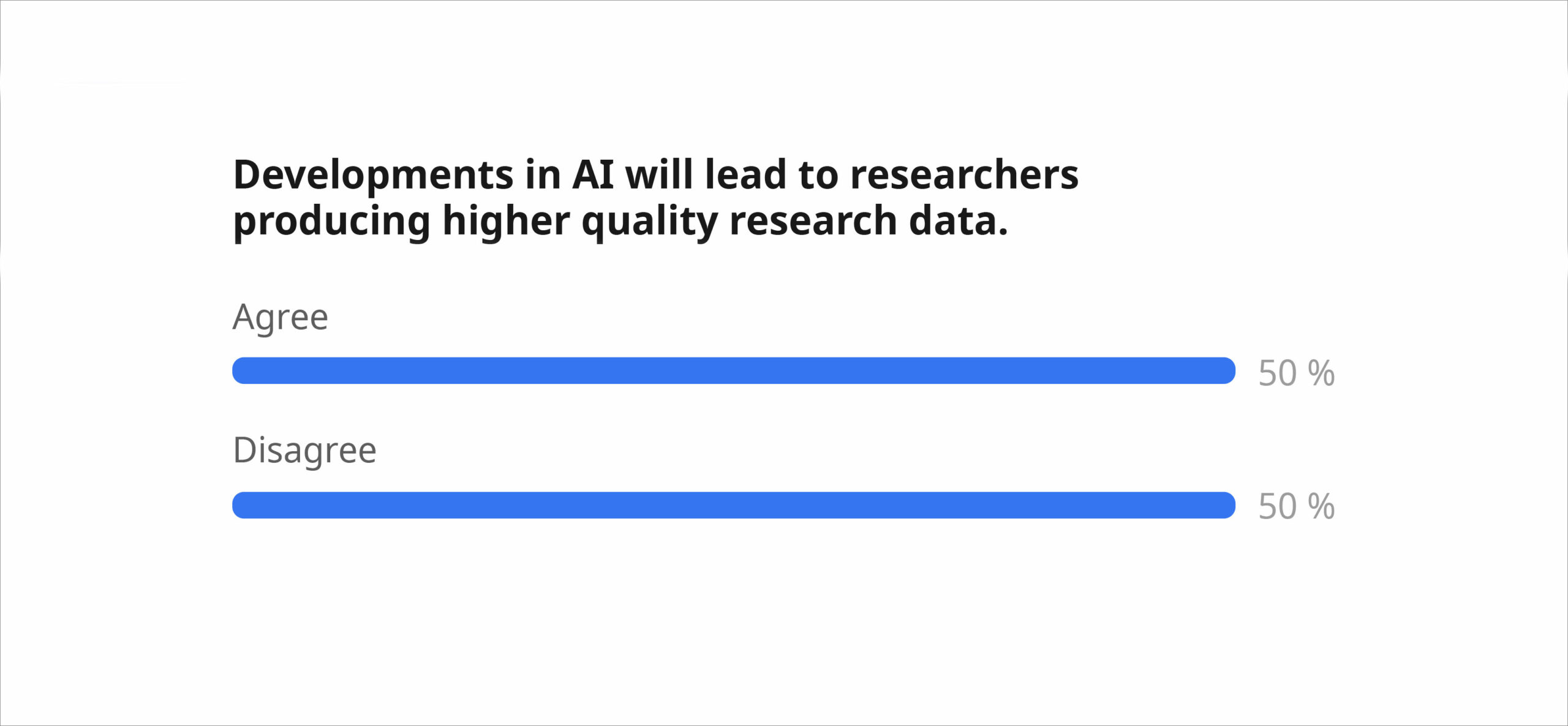
Consequently, the remaining session focused on this statement and participants collected arguments for and against in groups, which were then put up for a heated debate in the room. Some voices emphasised that AI can provide substantial assistance in research tasks such as data handling, workflow development, quality assessment and others. These voices also added some conditions, such as competent humans being in the loop and AI being used as a tool rather than a “magic machine”. Others argued that the reason for the low prevalence of high quality, FAIR and Open Data is not mainly a technological one. Therefore, AI will not be able to fix this issue, but may even contribute to more bad or false data. Concerns also included technical limitations of LLMs (such as hallucinations and biases) and the difficulty of obtaining trustworthy and explainable AI tools. Hopefully, such discussions will help us as a community to play an informed and active role in shaping what the correct answer of the statement will be.
- About the author:Ilona Lipp is the Open Science Officer at the University of Leipzig, promoting and supporting transparency and integrity in research. She has over 12 years of research experience in interdisciplinary neuroscience in Austria, the UK, and Germany. With additional training in coaching, mediation and didactics, she now helps scientists navigate academia and optimise their research practices. She can be found on LinkedIn at LinkedIn.
Streamlining Data Publication: Automatic Metadata
and Large Datasets in the Age of AI
by Anna Jacyszyn, Felix Bach, Tobias Kerzenmacher
and Mahsa Vafaie
Discussion Session
The session began with a presentation of solutions for automatic metadata extraction and large-scale data handling, followed by a discussion on how these innovations help create a more streamlined and scalable data-publication workflow.
The warm-up question “Would you trust AI more than a human to create descriptive metadata?” already revealed how divided we are when it comes to AI advancements in research data management. Most of our audience (67%) was in favour of “Human-curated, AI-generated” metadata. This was followed by 21% who voted for exclusive metadata generation by “humans”, and 8% “AI-curated, Human-generated”.

This question “Do you think that with the current AI developments, in 10 years from now we will NOT need metadata anymore?” really polarised the discussion. 30% of the audience agreed with this statement, while 40% think that metadata will still be needed in the future. We discussed reasons for and against, mentioning that due to ethical aspects, especially for sensitive data, AI cannot replace humans in annotating the data. We emphasised that in humanities, metadata creation is part of the research process and requires expertise. Also, the boundary between data and metadata in humanities is fuzzy. When deploying LLMs to create metadata, we also need to be mindful of human versus AI-generated data. Looking into the future, we noted that in 10 years the LLMs will be much more mature than we imagine today. As AI-generated metadata grows, questions of reliability and responsibility will become increasingly important for ensuring originality and trust in research data.
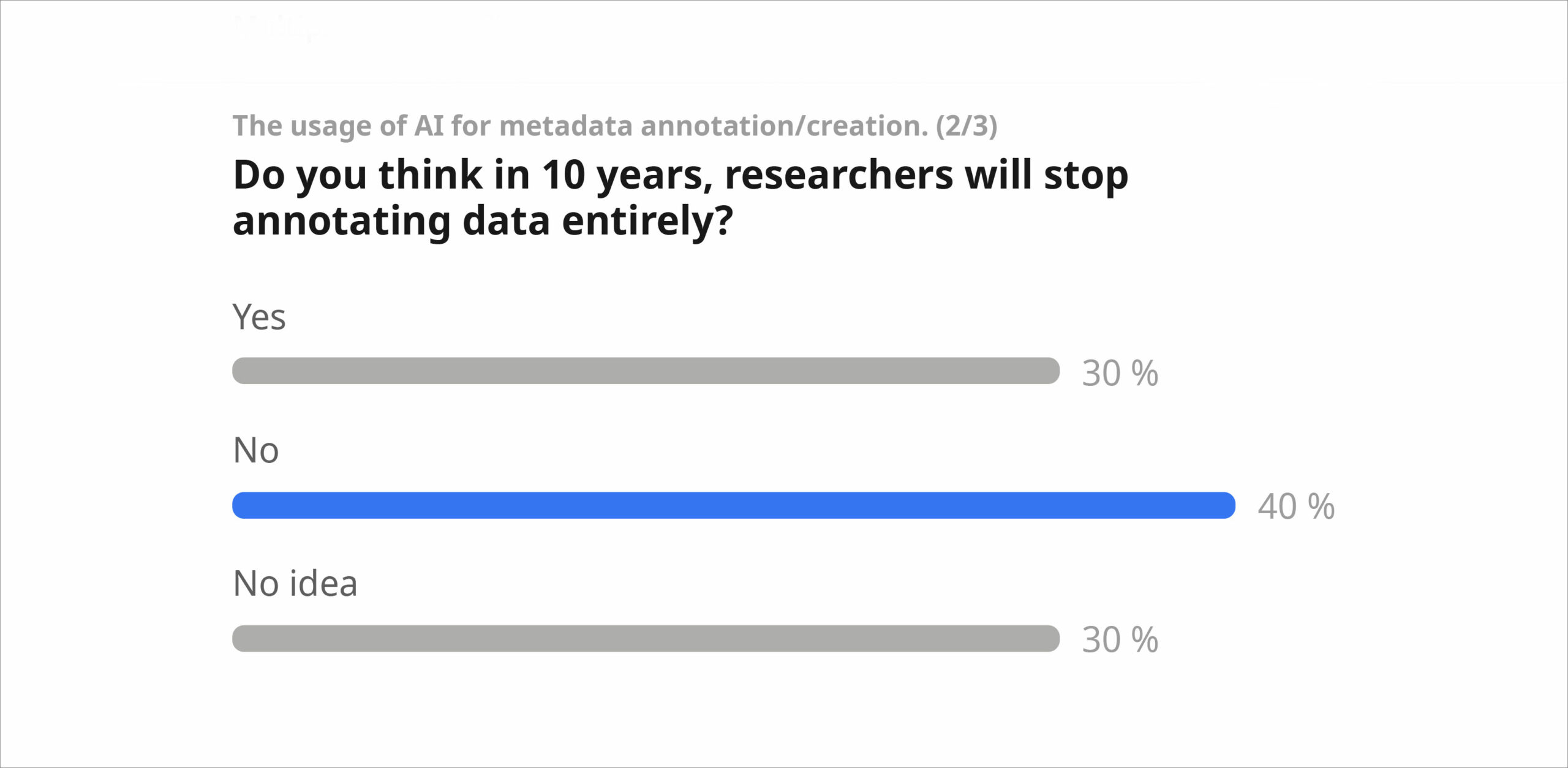
A more detailed report on the session will be published as a collaboration between session organisers and volunteering participants. The session presentation is available onZenodo.
About the authors:
- Anna Jacyszyn is a postdoctoral researcher in the Information Service Engineering (ISE) group at FIZ Karlsruhe – Leibniz Institute for Information Infrastructure. She holds a PhD in astrophysics. Anna is working mostly as a coordinator of the Leibniz Science Campus “Digital Transformation of Research” (DiTraRe), where she navigates collaborative efforts between interdisciplinary working groups. A special focus of her work is AI4DiTraRe: studying and applying different AI methods in four DiTraRe use cases. She can be found on LinkedIn.
- Dr Felix Bach is Head of the Research Data Department at FIZ Karlsruhe and Scientific Coordinator of the Leibniz ScienceCampus DiTraRe (Digital Transformation of Research) . He co-leads the NFDI4Chem consortium and is actively involved in multiple NFDI consortia, advancing digital research infrastructures, interdisciplinary data services, and open science. His work centres on repository development, ELNs, data archiving and AI-ready data in the sciences and humanities.
- Dr Tobias Kerzenmacher is researcher in the Research Data Management Group of the Institute of Meteorology and Climate Research (IMKASF) at the Karlsruhe Institute of Technology (KIT). His work centres on atmospheric physics and chemistry, with a particular focus on understanding stratospheric processes by combining Earth system models and observational data. His scientific interests include large scale atmospheric circulation – especially the Quasi Biennial Oscillation (QBO) – and research integrity issues. He is a member of DiTraRe (Digital Transformation of Research) and contributes to the use case Publication of Large Datasets.
- Mahsa Vafaie is a PhD student and a researcher in the Information Service Engineering group at FIZ Karlsruhe – Leibniz Institute for Information Infrastructure. She is currently working on a digitalisation project that aims to create a knowledge graph for contextualisation of historical knowledge derived from collections of documents, records, and materials directly linked to the compensation process for the atrocities of the National Socialist regime in Germany (“Themenportal zur Wiedergutmachung nationalsozialistischen Unrechts”). She is also involved in scientific and teaching activities in the fields of Knowledge Graphs and Semantic Web, at Karlsruhe Institute of Technology (KIT) and in other conferences and venues relevant to these fields. She can be found on Linkedin and Mastodon.
Open Science in Decline? Data Sharing between
AI commons and predatory capture
by Katja Mayer, Jochen Knaus and Stefan Skupien
The session explored tensions and opportunities of maintaining openness under increasingly complex technological conditions, addressing three key questions. It built on the results of the „Yes, We Are Open” event in Berlin in March 2025. (Discussion Paper, PDF | Policy Paper, PDF)
Question 1 – Data Sharing, AI Commons & Predatory Capture – Are these all old problems, or new?
Growing tensions emerged between openness ideals and AI-age challenges. Security concerns and political contexts increasingly constrain openness. A Canadian example illustrated how hospitals hesitate to publish data due to AI-driven re-identification fears. Moreover, copyright, IP, and data ownership remain major obstacles for open research data providers. For instance, LLMs remix material “beyond the original,” blurring fair use and creativity lines.
A recurring issue is the lack of recognition for Open Data contributors, worsened by AI-driven reuse. A word cloud “generated from participants” responses, captured the following tensions seen by the participants: security, copyright, privacy, recognition, dual-use, accountability, and corporate greed.

Question 2 – What kinds of recognition and support are needed?
Participants emphasised lacking structural incentives, mainly because Open Data doesn’t count as proper research output. Suggestions included linking funding to transparency, standardised credit systems, and discipline-specific guidelines. A key demand was the repeated emphasis on training. Additionally, calls for FAIR data services, ethical safeguards, and fair cooperation models were voiced to address imbalances where academic data feeds proprietary AI.
Question 3 – Do we need new models of openness
Most participants agreed traditional Open Science models no longer fit AI realities. Calls emerged for reciprocal or conditional openness with clearer accountability rules. Ideas included adapted licenses, paid commercial use, and collectively governed protection of commons. Yet strong unease persisted – some felt “it’s already too late,” others warned against retreating from openness as a key value in science.
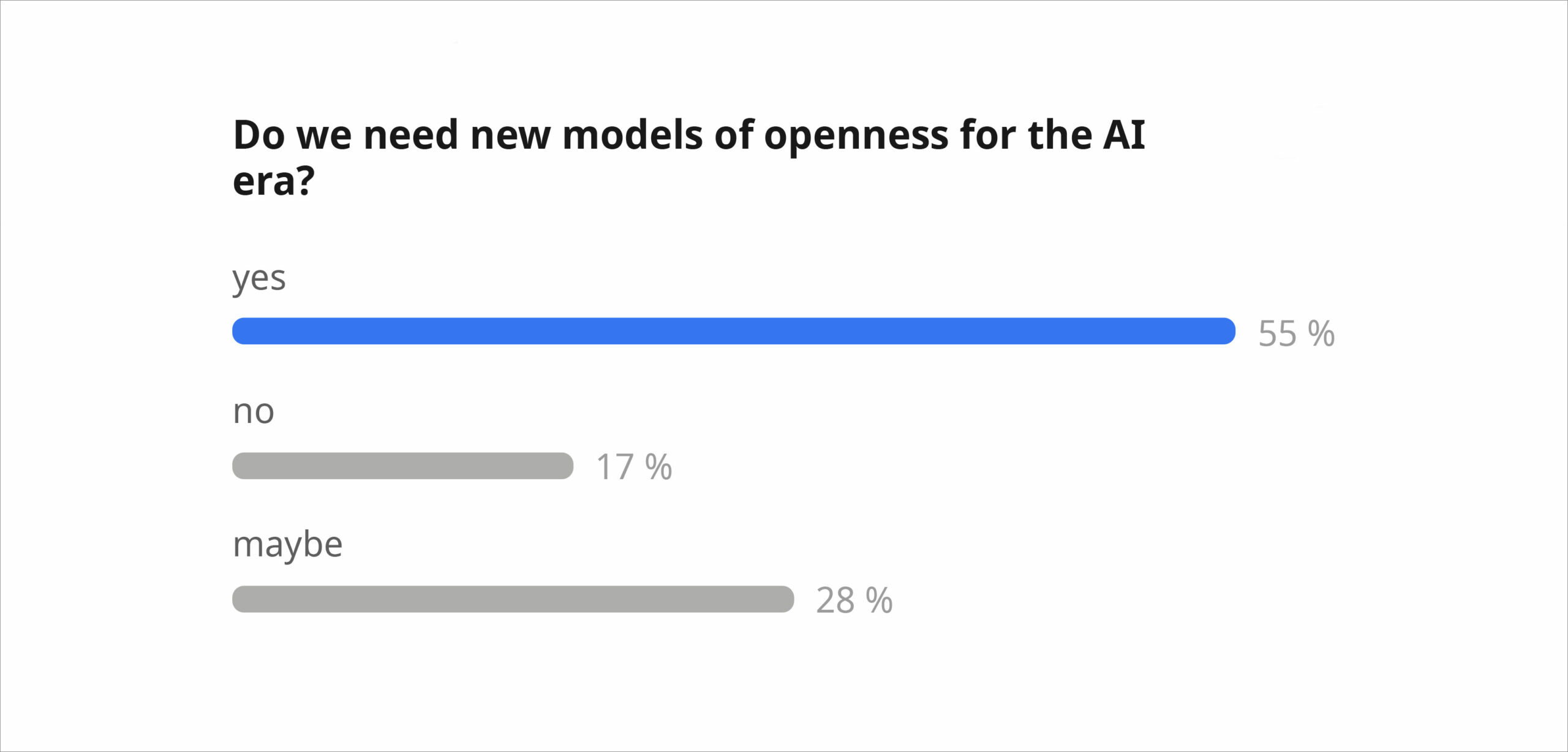
About the authors:
- Katja Mayer is a sociologist and science and technology studies scholar at the University of Vienna, specializing in the politics of Open Science, digital infrastructures, and AI. Her research critically examines how data practices co-constitute and reflect social relations. With experience in both academia and the IT industry, she integrates practical and theoretical perspectives in her teaching and policy engagement. She is also a senior scientist at the Center for Social Innovation (ZSI) in Vienna, where she collaborates on participatory approaches to evaluating Citizen Science.
- Jochen Knaus: With a broad background in computer science and literary studies and over 20 years of experience in life sciences research, research data management and infrastructure related topics in large collaborative projects. He is interested in all areas of Open Science and works as an officer for research information and AI at the Weizenbaum Institute.
- Dr. Stefan Skupien has been working as scientific coordinator for Open Science in the Center for Open and Responsible Science of the Berlin University Alliance since 2020, combining his experience in research management, international science studies, and Open Science.
Promoting Shared Understanding and Global Pathways for
Open Science and AI in Emerging Research Environments
by Firas Al Laban and Jan Bernoth
The discussion session began with an introduction of the “NFDIxCS-Projekts” and an overview of how to promote shared understanding and global pathways for Open Science and AI in emerging research environments.
To set the stage, participants were invited to vote on a guiding question to prioritise the starting point for a global pathway. The options were (i) Policies and Strategies and (ii) Cultural Influences and Capacity Building.

The poll results were close and competitive, reflecting the importance of both dimensions. Ultimately, the group selected cultural influences and capacity building as the preferred starting point for collective action.
The discussion then centered on two key questions. The first was: How does culture influence research? Participants shared many insightful perspectives, addressing the impact of cultural factors on the research environment and the challenges that might hinder international collaboration.
This led to the second question: Could cultural barriers hinder opening science? Participants agreed that while such obstacles exist, they also present valuable opportunities for learning, adaptation, and dialogue across research communities.
Several practical actions for enabling capacity building in Open Science and AI were highlighted. Participants emphasised that train-the-trainer programs are essential for scaling skills and practices. The human factor – trust, motivation, and cultural sensitivity – remains a key enabler of success. At the same time, tailoring open-access teaching materials to local contexts, languages and institutional needs ensures equitable participation.
The session concluded with a shared commitment to foster the formation of interest-based communities and to establish continuous, collaborative discussions on Open Science and AI within emerging research environments.
About the authors:
- Firas Al Laban is an academic and researcher with a robust background in Computer Science and Mathematics. He holds a Ph.D. in Knowledge Management Systems and has international experience in higher education, including teaching diverse subjects, supervising student research, and contributing to global conferences and peer-reviewed publications. He is currently a scientific staff member at the University of Potsdam, where he works on research data and software management within the NFDIxCS project. His work is guided by a deep commitment to innovation, Open Science, and the advancement of technology and education through sustainable, research-driven practices. He can be found on LinkedIn.
- Jan Bernoth, M.Sc., is a computer scientist working as a researcher, team lead, and PhD candidate at the chair of Prof. Dr. Ulrike Lucke at the University of Potsdam. Guided primarily by his work in NFDIxCS, his research focuses on supporting research data and software management by designing the necessary architecture behind the Research Data Management Container, in collaboration with the consortium and the computer science community. His PhD research explores how to visualise research topics in non-scientific media to support scientists in their science communication efforts. Follow him on Mastodon.
AI in Peer Review: Promise, Pitfalls, and Practical Pathways
by Johanna Havemann, Nancy Nyambura and Tim Errington
How could AI transform – and potentially disrupt – the peer-review ecosystem? That was the central question in our session. Co-led by Johanna Havemann (Access 2 Perspectives) and Tim Errington (Center for Open Science), with remote support from Nancy Nyambura (Access 2 Perspectives), the session invited live ideation around opportunities, risks, and responsible pathways forward. Following short input speeches by Johanna and Tim, the format was a hot-seat panel, with rotating panelists from the audience who had been encouraged to take seats spontaneously.
The participants expressed both excitement and caution over the benefits and threats of AI in the Peer Review process. Many welcomed its ability to support language editing, detect formal issues, summarise manuscripts, or suggest reviewers. Others raised concerns about bias, opacity, intellectual-property risks, and the fear that automated feedback might influence – or even overshadow – human judgement. A strong consensus emerged around a “human-in-the-loop” model: AI may accelerate screening and quality checks, but final evaluations must remain grounded in human expertise.
Promising use cases included automated preprint screening, metadata and reference checks, reviewer-matching, and tools that help authors pre-review their own work before submission. Yet participants stressed the need for transparency: journals should disclose which tools were used, for which tasks, and how decisions were made.
Ethical principles highlighted during the session included fairness, openness about algorithms and processes, separation of automated and personal feedback, and the continued value of human critical thinking. Best-case scenarios involved AI reducing reviewer burden and improving manuscript clarity; worst-case scenarios warned of unregulated AI generating undetectable fabricated research or diminishing human reasoning.
The session closed with shared commitments: experimenting with AI tools, starting institutional conversations, updating guidelines, and fostering collaborative, responsible development of AI-supported peer review. Participants mentioned that they will move on feeling inspired, reflective, and aware that meaningful progress requires clearer definitions and a shared understanding.
To learn about the detailed aspects that were discussed during this session and receive follow-up information to engage more on the topic, email .
Read more: AI in Peer Review: Fairer or Faster. A Personal Reflection by Nancy Nyambura.
About the authors:
- Jo Havemann, PhD, is the Founder & CEO of Access 2 Perspectives, where she delivers training and consulting in Open Science communication and digital research management. She holds a PhD in Evolution and Developmental Biology and is a certified trainer recognised by the German Chamber of Industry and Commerce. Jo is also co-founder and lead coordinator of AfricArXiv, the open scholarly repository enhancing the visibility of African research. Her expertise – including global research equity, Open Science workflows, and science communication – is informed by experience with NGOs, a science startup, and the UN Environment Programme.
- Nancy Nyambura is an early-career professional with over 4 years of experience driving community-based capacity building initiatives that empower women, youth, and people living with disabilities through skills development and entrepreneurship training. She is deeply committed to advancing social sustainability through inclusive and equitable support systems. Nyambura also works at Access 2 Perspectives as a Research Affiliate, supporting AfricArXiv in Open Knowledge advocacy and stakeholder engagement across the African research ecosystem, with a particular focus on the responsible use of emerging technologies in academia. She can be found on LinkedIn.
- Tim Errington is the Senior Director of Research at the Center for Open Science (COS) that aims to increase openness, integrity, and reproducibility of scientific research. In that position he conducts and collaborates with researchers and stakeholders across scientific disciplines and organizations on metascience projects aimed to understand the current research process and evaluate initiatives designed to increase reproducibility and openness of scientific research. These include large scale reproducibility projects such as the Reproducibility Project: Cancer Biology and the DARPA supported Systematizing Confidence in Open Research and Evidence (SCORE), and evaluation projects of new initiatives such as Open Science badges, Registered Reports, and a novel responsible conduct of research training.
How FAIR-R Is Your Data? Enhancing Legal and
Technical Readiness for Open and AI-Enabled Reuse
by Vanessa Guzek and Katharina Miller
During the OSC 2025 in Hamburg, our solution session “How FAIR-R Is Your Data?” brought together around twenty participants to test real datasets against the extended FAIR-R framework — Findable, Accessible, Interoperable, Reusable, and Responsibly licensed for AI reuse. Working in six groups, participants audited datasets such as Open Images, Dryad, UK Data Service, FDZ-Bildung, and GoTriple metadata.
The teams stress-tested the FAIR-R checklist, identifying recurring barriers: missing or scattered licenses, NC/ND restrictions, ambiguous third-party rights, unclear provenance, and absent machine-readable license or metadata fields. Ethical and GDPR aspects were also often missing for human or qualitative data.
Participants proposed concrete upgrades: co-locating human- and machine-readable licenses (SPDX/schema.org), adding explicit ethics and data protection checks, clarifying collection-level authorship and citation, and strengthening repository preservation and PID strategies. The revised FAIR-R Checklist v1.1 will incorporate these improvements validated through the group work.
In summary, none of the reviewed datasets fully met the FAIR principles – and therefore not FAIR-R either. The session showed that while FAIR is necessary, FAIR-R is essential to make Open Data legally sound, machine-actionable, and trustworthy for AI reuse.
The session structure, slides, and FAIR-R checklist are available on Zenodo. The session report, the FAIR-R Checklist v1.1, and the mini audit “snapshots” will also be published there.
About the authors:
- Vanessa Guzek Hernando is a lawyer admitted to practice in both Germany and Spain with over a decade of experience in intellectual property law, international legal frameworks, and policy development. She joinedMiller International Knowledge (MIK) as the Legal and Policy Director for IP4OS, where she leads strategic legal initiatives at the intersection of intellectual property and Open Science. Since beginning her legal practice in 2013, Vanessa has specialised in cross-border legal strategies, compliance, and regulatory frameworks. Her deep knowledge of international private law, distribution law, and liability law uniquely positions her to support and shape innovative IP management within open research environments.
- Katharina Miller is an accomplished lawyer and expert in legal compliance, corporate governance, and sustainability, with over 15 years of professional experience. As a partner at Miller International Knowledge (MIK), she specializes in aligning business practices with international standards, focusing on intellectual property (IP), ethics, and corporate accountability. Katharina is a seasoned educator and advisor, actively contributing to capacity-building projects such as IP4OS, where she brings her expertise to promote the synergy between IP and Open Science. She has served as a Work Package and Task Lead for ethical frameworks in EU-funded projects, including H2020 Path2Integrity or H2020 DivAirCity, and is a trusted consultant on data protection and regulatory compliance. Katharina is passionate about fostering innovation, responsible governance, and inclusion, consistently advocating for sustainable and ethical business practices in the international arena.
Marbles – Upcycling research waste and making
every effort count in the era of Open Science
by Pablo Hernández Malmierca and Isabel Barriuso Ortega
The founders of Research Agora, an innovative platform aimed at recognising invisible research outputs, introduced their novel publication format, Marbles. The session started with an overview of two important challenges in research: research waste and the reproducibility crisis of research articles. We then moved on to how to address these issues in the current framework of Open Science and assessment reform.
Marbles were proposed as a solution to these issues. These are short, peer-reviewed and open-access reports linked to already published literature, that report research results that are routinely done in the course of research but do not fit the traditional article: replications, failed replications, alternative methods, exploratory hypotheses and negative results. Marbles have the potential to add to the information reported on research articles collaboratively, and to measure their reproducibility and impact. Besides, they recognise the invisible work from researchers who carry out these experiments, reviewers who revise these publications, and authors of the linked article, who will have metrics on the quality of their published research.
After this presentation, participants engaged in a lively discussion that highlighted the importance of complementing this community initiative with a strategy from research institutions and funding bodies. This should be a joint effort to reduce research waste, improve reproducibility, and support the recognition of diverse outputs. Finally, they pointed out the importance of Marbles appearing in indexing aggregators (for instance OpenAlex, OpenAIRE or PubMed) and the incentives of publishing this type of output as key factors in its usefulness in the long term.
The session slides and report are available on Zenodo.
About the authors:
- Pablo Hernández Malmierca is the CEO and co-founder of Research Agora, a platform to foster a more accessible, transparent, and collaborative research ecosystem. He holds a PhD in Stem Cells Biology and Immunology (Heidelberg University) and has over 10 years of experience in research in Spain, UK, Switzerland, and Germany. He knows the ins and outs of academic and industry research, and has authored important publications. He always wanted to be a researcher, but now his passion is improving research culture worldwide. He can be found on LinkedIn.
- Isabel Barriuso Ortega is the COO and co-founder of Research Agora, a platform to foster a more accessible, transparent, and collaborative research ecosystem. She holds a PhD in Neuroscience from Heidelberg University. With over 8 years of experience working in Spain, France, and Germany, she authored important publications on Systems Neuroscience. She is an expert data analyst and is passionate about science communication. Isabel is also an active member of AMIT-MIT, where she works to advance gender equality and reduce discrimination in research and STEM. She can be found on Bluesky and Linkedin.
Open Science Capacity Building in times of AI:
Finding solutions with the GATE
by Anika Müller-Karabil and Marie Alavi
Over 40 participants from research, education, libraries, data and software professions, as well as from policy and funding institutions joined the GATE Session to explore how Open Science can thrive at the intersection with AI. The session drew on materials and data from the Open Science Learning GATE, which provides an infrastructure for continuous knowledge exchange on Open Science, connecting diverse stakeholder groups and offering guidance on current developments.
Participants co-created target-group-specific actions to build Open Science capacity in seven multidisciplinary groups, using GATE-provided personas (for instance, early-career researcher, programme officer) and guiding thoughts (such as bias-free AI, privacy) to focus their discussions.
The groups proposed conceptual directions and identified needs rather than ready-to-implement solutions, highlighting priorities that cut across communities. These included building trust and transparency, embedding Open Science early in research training, promoting flexible, discipline-sensitive frameworks, and ensuring responsible use of AI tools. Researchers emphasised integrating Open Science into training and aligning motivation with incentives. Librarians and educators highlighted their bridging role, supporting practical guidelines and ethical AI use. Technical experts focused on reproducibility and reliable infrastructures, while policy and funding actors stressed coherence, feasibility, and sustained support.
The session reinforced that advancing Open Science in an AI-driven (research) landscape requires collaborative action across all communities. By leveraging the mission and resources of GATE, stakeholders can connect practice with policy and co-create strategies that advance Open Science and keep it both principled and practical.
The session’s structure and slides are available on Zenodo, and the session report will also be published there.
About the authors:
- Anika Müller-Karabil works as research staff at Bremen University the Language Centres for the Universities in Bremen. She is an expert in the field of language teaching, learning and testing, and her research interests include academic language requirements in higher education, language education in the context of AI, and Open Science. Anika is a co-developer of GATE and member of the Network for Education and Research Quality (NERQ).
- Marie Alavi is a research associate at Kiel University. Her main research focus is the intersection of Responsible Conduct of Research, Open Science, Intellectual Property and AI. She is the co-developer of the GATE and member of the Network for Education and Research Quality (NERQ), co-leading the special interest groups on Open Science (where GATE has its origins) and Open Science & Intellectual Property. Marie is currently involved in the IP4OS. Prior to that, she was involved with Path2Integrity and HAnS, where she conducted research focused on research integrity and the role of AI in higher education.
AI, plagiarism and text recycling: information resources
for academic authors
by Aysa Ekanger
In this solution session, participants looked at how journals can help academic authors use their knowledge of the issues of plagiarism and text recycling to avoid problematic uses of generative AI in their manuscripts. The participants had to work with one of the prepared tasks to produce informational resources, a flowchart, FAQ, or a list of issues to be addressed in a journal policy, and they had excerpts from the “Living guidelines on the responsible use of generative AI in research” and Text Recycling Research Project for reference.
Throughout their proposed solutions, the participants underlined the importance of transparency and human oversight. The concrete proposed measures to increase the reliability of research in case GenAI tools have been used, included a standardised AI use statement, inclusion of DOIs in the reference lists (to mitigate the reference hallucination problem) and the utilization of knowledge graphs as a way to prevent plagiarism of ideas.
The session did not provide results that can be directly reused by journals’ editorial teams, but it provided a useful insight into how these issues should be presented in workshops for journal editors who are looking to update their journal policies to encompass AI use. Session materials are available on Zenodo.
About the author:
- Aysa Ekanger is the coordinator of Septentrio Academic Publishing, a diamond OA journal publishing service at UiT The Arctic University of Norway. In the Septentrio team, she works with user support and editor training. She is also one of the university library’s experts on Creative Commons licenses, and works with other Open Access related issues. Aysa has a PhD in Theoretical Linguistics from the University of Groningen, Netherlands. She can be found on Bluesky and LinkedIn.
Panel Discussion “The Role of Open Science
in Safeguarding the Research Enterprise”
by Tim Errington
In a panel discussion on “The role of Open Science in safeguarding the research enterprise” with Julia Prieß-Buchheit from Kiel University, Jez Cope from the British Library, and Peter Suber from Harvard Library (joining remotely), each panelist started with a short impulse statement. The panelists highlighted the range of threats to the research enterprise, ranging from the unintended use of research content and generation of fabricated content to the political influence on the research process and outputs.
Following these impulse statements, the discussion continued around four guiding questions ranging from resilience, to how concepts like Open Data and Open Access and open processes like open peer review contribute to credibility, to strategies, such as intellectual property, that can be used to balance Open Science principles with the need to protect content. Questions from the audience helped guide the discussion. The discussion ranged from how to build redundancy in the research ecosystem, such as the dark archive of arXiv that TIB has built, to how to communicate the value of Open Science to skeptics and policy makers. The discussion highlighted how globally shared science is harder to censor and can contribute to a more resilient research enterprise.
About the authors:
- Tim Errington is the Senior Director of Research at the Center for Open Science (COS) that aims to increase openness, integrity, and reproducibility of scientific research. In that position he conducts and collaborates with researchers and stakeholders across scientific disciplines and organizations on metascience projects aimed to understand the current research process and evaluate initiatives designed to increase reproducibility and openness of scientific research. These include large scale reproducibility projects such as the Reproducibility Project: Cancer Biology and the DARPA supported Systematizing Confidence in Open Research and Evidence (SCORE), and evaluation projects of new initiatives such as Open Science badges, Registered Reports, and a novel responsible conduct of research training.




Open Science & AI: Not the end – just the beginning
The Open Science Conference brought together participants across disciplines and career stages. The atmosphere was notably constructive: despite the controversy around OS & AI, participants engaged energetically, challenged assumptions, and co-created concrete solutions to real problems. The event made clear both the urgency and relevance of the topic, and how much remains unsettled. Rather than offering closure, OSC 2025 felt like a beginning: a shared commitment to continue the conversation and the collaboration, advancing the technological, ethical, and pedagogical questions that will shape open, trustworthy AI and Open Science.
Materials such as presentations, session summaries, and posters are published on Zenodo. Recordings of the keynotes, panel discussion, and discussion session presentations are available on YouTube.
This might also interest you:
- ZBW press release: “Open Science Conference shows: Trustworthy AI requires open and traceable data”
- Open Access Days 2025: Goal Achieved – or how can it (Ever) be Accomplished?
- Barcamp Open Science 2025: From Threats to Collective Resilience
- Ambitious Pioneer for Open Science: These are the top Priorities at the EOSC Association


Practice of Research Data Management: Findings from an IFLA Project on Data Curators

Promoting OER: How to Create an Open Textbook

Fidus Writer: Modern Writing Tools for the Social Sciences
View Comments

AI in Libraries: How Libraries can Live Up to Their Responsibilities
Given the great potential but also the considerable risks and known negative effects...