
Open Science Conference 2025: Eine aussichtsreiche Zukunft für Open Science und KI gestalten
Bei der diesjährigen Open Science Conference ging es ausschließlich um die Themen Open Science und KI. Die Teilnehmenden betrachteten die Chancen und Herausforderungen, die an ihrer Schnittstelle auftreten. Sie erörterten, wie KI verantwortungsbewusst in Forschungsprozesse integriert werden kann und wie im Gegenzug vertrauenswürdige KI auf der Grundlage vertrauenswürdiger Daten aufgebaut werden kann.
von Marie Alavi, Felix Bach, Jan Bernoth, Aysa Ekanger, Tim Errington, Vanessa Guzek, Johanna Havemann, Anna Jacyszyn, Tobias Kerzenmacher, Jochen Knaus, Firas Al Laban, Ilona Lipp, Pablo Hernández Malmierca, Katja Mayer, Katharina Miller, Anika Müller-Karabil, Nancy Nyambura, Isabel Barriuso Ortega, Guido Scherp, Stefan Skupien, Mahsa Vafaie und Nicolaus Wilder
Vom 8. bis 9. Oktober 2025 kamen über 200 Teilnehmende aus 27 Ländern in Hamburg und online für die Open Science Conference zusammen, die sich in diesem Jahr mit der Beziehung zwischen Open Science und künstlicher Intelligenz (KI) befasste. Da die Entwicklungen in diesem Bereich weiterhin hochdynamisch sind, besteht ein großer Bedarf an Austausch und Zusammenarbeit. Aus diesem Grund wurde die Konferenz in hoch interaktiver Form gestaltet, um Debatten anzuregen und konkrete Lösungen zu entwickeln. In seiner Eröffnungsrede ermutigte Prof. Dr. Klaus Tochtermann die Teilnehmenden, “kritische Fragen zu stellen und sich darüber auszutauschen, was in ihrem eigenen Forschungskontext funktioniert und was nicht”. Zwei inspirierende Keynotes bildeten den Rahmen für das Konferenzprogramm.
Dr. Erik Schultes betrachtete in seiner Keynote „FAIR and Verifiable: The Role of FAIR Digital Objects in Trusted AI“, wie sich die Prinzipien von FAIR Data (Findable, Accessible, Interoperable, Reusable) und künstliche Intelligenz gegenseitig verstärken können. Er betonte, dass KI-Systeme zwar komplexe wissenschaftliche Erkenntnisse generieren können, ihre Vertrauenswürdigkeit jedoch von der Qualität und FAIRness der zugrunde liegenden Daten abhängt. An der Universität Leiden demonstrierte das Team von Schultes diese Synergie. Es nutzte die FAIR-Plattform SENSCIENCE und ihre KI Clara, um automatisch einen Artikel zu generieren, der ein Peer-Review durchlief, einen interaktiven Daten-Explorer und einen Podcast, wobei eine Masterarbeit mit ihren Daten als einzige Basis verwendet wurde. Seine Gruppe setzt auch Nanopublikationen auf der Grundlage von FAIR Digital Objects ein, um standardisierte, maschinenlesbare Metadaten zu erstellen, die Datensätze, Methoden und Publikationen miteinander verknüpfen und so durchsuchbare institutionelle Wissensgraphen bilden. Zudem hob er das Projekt FAIR AI Attribution (FAIA) hervor, das KI-generierte Inhalte mit Tags versieht, um Transparenz zu gewährleisten. Eher allgemeinerer Natur waren andere von ihm angesprochene Themen, etwa die Überlastung des heutigen Internets durch KI-generierte Daten. Schultes kam zu dem Schluss, dass vertrauenswürdige KI sowohl FAIRe Daten nutzen als auch produzieren sollte, um offene und überprüfbare Wissenschaft zu ermöglichen.
In ihrer Keynote „Data Infrastructures and Data Competencies as a Foundation for AI Projects” hob Prof. Dr. Sonja Schimmler hervor, wie robuste Dateninfrastrukturen und Datenkompetenzen das Rückgrat einer vertrauenswürdigen und transparenten KI-Forschung bilden. Sie betonte, dass der Aufstieg generativer KI und großer Sprachmodelle FAIR-konforme Datenökosysteme erfordert, um Reproduzierbarkeit, Transparenz und ethische Verantwortung sicherzustellen. Im Rahmen von Projekten wie NFDI4DS, Datenkompetenzzentren oder QUADRIGA entwickeln die Initiativen Infrastrukturen und Schulungsprogramme, die KI-Methoden mit Open-Data-Prinzipien, Wissensgraphen und FAIRen digitalen Objekten verknüpfen. Verbundene Repositorien, SPARQL-Endpunkte und automatisierte Metadatenmetriken machen Datensätze und Modelle auffindbar, vertrauenswürdig und wiederverwendbar. Der Vortrag unterstrich Open Science als Voraussetzung für verantwortungsvolle KI – nicht als bloßen Datenaustausch, sondern als kulturellen Wandel hin zu kollaborativen, transparenten und von Maschinen interpretierbaren Forschungspraktiken, die auf den Prinzipien FAIR, CARE und TRUST basieren, und so Transparenz, Verantwortlichkeit und Wiederverwendbarkeit in großem Maßstab gewährleisten.
Über die Keynotes hinaus boten Discussion und Solution Sessions Teilnehmenden die Möglichkeit, sich eingehender mit bestimmten Aspekten von Open Science und KI zu befassen. Eine Podiumsdiskussion, die sich mit der Rolle von Open Science für den Schutz des Forschungsbetriebs befasste, rundete das Programm ab. In diesem Bericht teilen Session-Veranstaltende ihre Einblicke und wichtigsten Erkenntnisse.
Chancen und Risiken an der Schnittstelle von KI
und offenen Forschungsdaten
von Ilona Lipp
Die Session startete mit einer Abstimmung über drei kontroverse Aussagen. Die Mehrheit der fast 100 teilnehmenden Personen stimmte der Aussage zu, dass „mehr Forschungsdaten geteilt werden sollten, damit eine bessere KI entwickelt werden kann“ (80 %) und dass „die Verhinderung eines potenziellen Missbrauchs ihrer Daten bei der KI-Entwicklung NICHT in der Verantwortung einzelner Forschender liegt“ (79 %). Die umstrittenste Aussage (genau 50 % zu 50 %) lautete: „Die Entwicklungen im Bereich der KI werden dazu führen, dass Forschende qualitativ hochwertigere Forschungsdaten produzieren.“
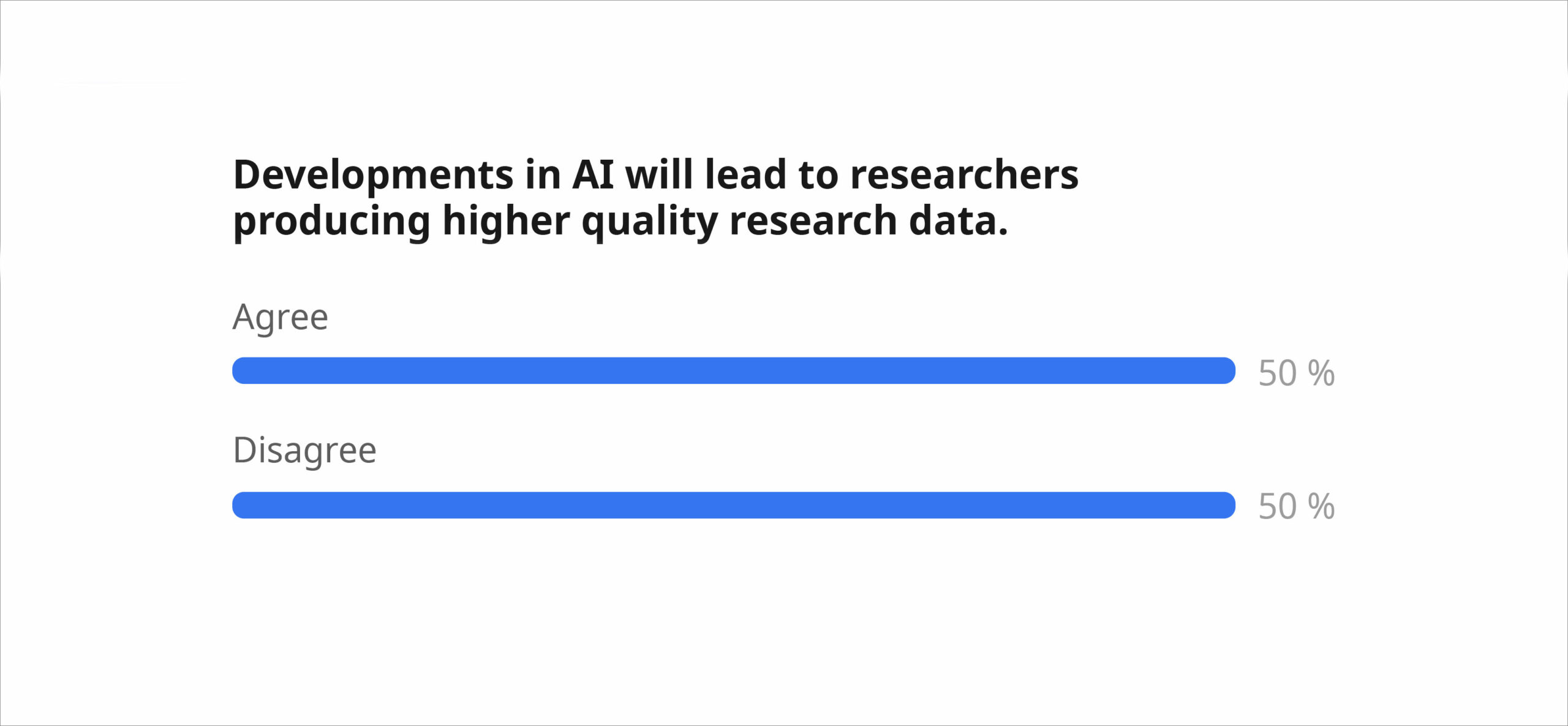
Daher konzentrierte sich die restliche Session auf diese Aussage, und die Teilnehmenden sammelten in Gruppen Argumente dafür und dagegen, die dann im Raum heiß diskutiert wurden. Einige Stimmen betonten, dass KI bei Forschungsaufgaben wie Datenverarbeitung, Workflow-Entwicklung, Qualitätsbewertung eine wesentliche Hilfe sein kann. Sie fügten auch einige Bedingungen hinzu, beispielsweise dass kompetente Menschen involviert sein müssen und KI als Werkzeug und nicht als „Zaubermaschine“ eingesetzt werden sollte. Andere argumentierten, dass die geringe Verbreitung hochwertiger, FAIRer und offener Daten nicht in erster Linie technologisch bedingt sei. Daher könne KI dieses Problem nicht beheben, sondern sogar zu mehr schlechten oder falschen Daten beitragen. Zu den Bedenken gehörten auch technische Einschränkungen von LLMs (wie Halluzinationen und Verzerrungen) und die Schwierigkeit, vertrauenswürdige und erklärbare KI-Tools zu bekommen. Hoffentlich helfen uns solche Diskussionen als Community dabei, eine informierte und aktive Rolle bei der Gestaltung der richtigen Antwort auf diese Aussage zu übernehmen.
- Über die Autorin:
Ilona Lipp ist Open-Science-Referentin an der Universität Leipzig und fördert und unterstützt Transparenz und Integrität in der Forschung. Sie verfügt über mehr als 12 Jahre Forschungserfahrung in der interdisziplinären Neurowissenschaft in Österreich, Großbritannien und Deutschland. Mit einer zusätzlichen Ausbildung in Coaching, Mediation und Didaktik hilft sie nun Wissenschaftler:innen, sich in der akademischen Welt zurechtzufinden und ihre Forschungspraktiken zu optimieren. Sie ist auf LinkedIn zu finden.
Datenveröffentlichung optimieren: Automatische Metadaten
und große Datensätze im Zeitalter der KI
von Anna Jacyszyn, Felix Bach, Tobias Kerzenmacher
und Mahsa Vafaie
Discussion Session
Eine Präsentation von Lösungen für die automatische Metadatenextraktion und die Verarbeitung großer Datenmengen bildete den Auftakt der Session, gefolgt von einer Diskussion darüber, wie diese Innovationen dazu beitragen, den Workflow für die Datenveröffentlichung zu optimieren und zu skalieren.
Die Aufwärmfrage „Würden Sie KI mehr als Menschen vertrauen, wenn es um die Erstellung beschreibender Metadaten geht?“ zeigte bereits, wie gespalten wir in Bezug auf die Fortschritte der KI im Forschungsdatenmanagement sind. Die Mehrheit unseres Publikums (67 %) sprach sich für „von Menschen kuratierte, von KI generierte“ Metadaten aus. Es folgten 21 %, die für eine ausschließliche Metadatengenerierung durch „Menschen“ stimmten, und 8 % für „von KI kuratierte, von Menschen generierte“ Metadaten.

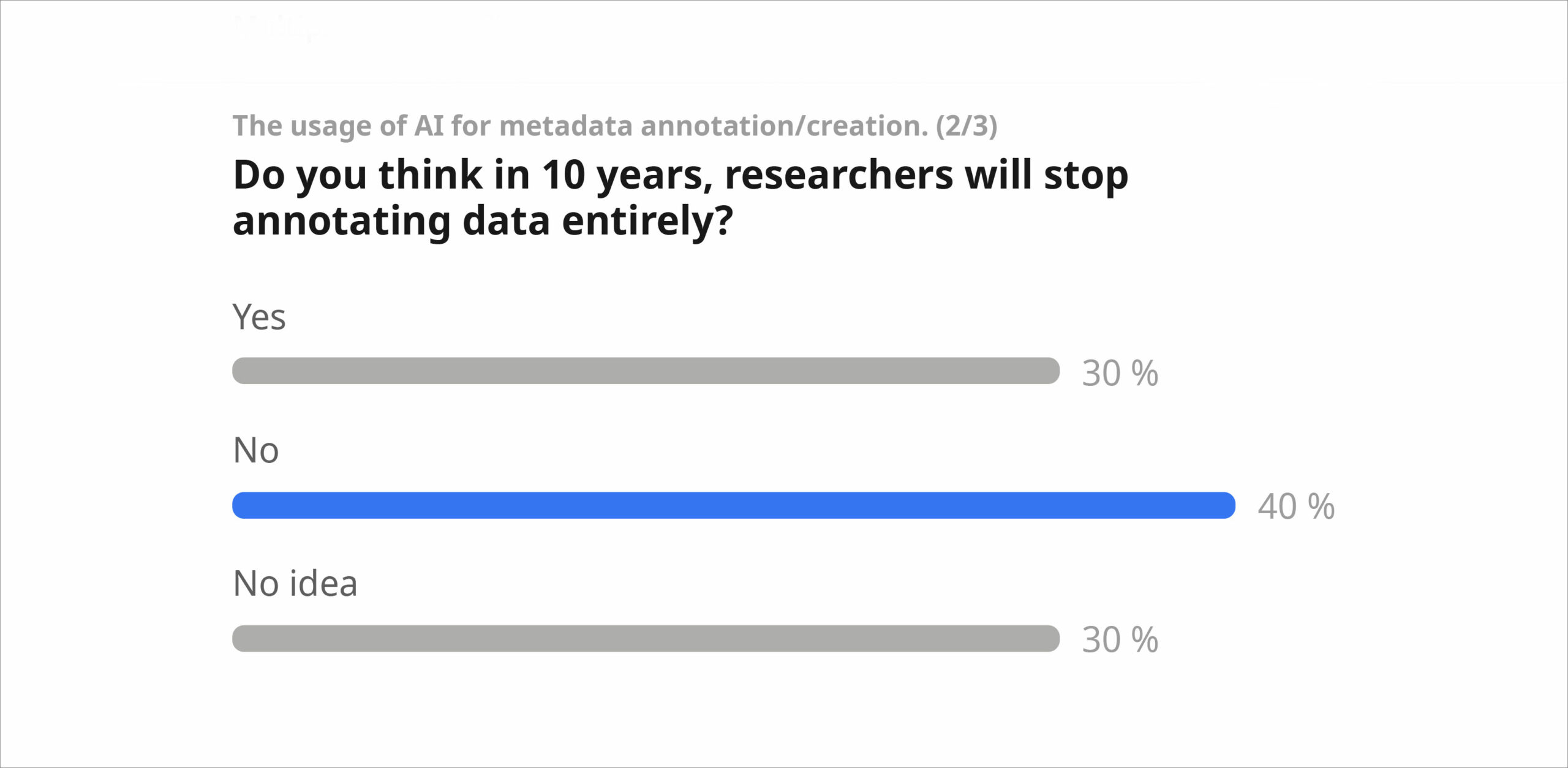
Die Frage „Glauben Sie, dass wir angesichts der aktuellen Entwicklungen im Bereich der künstlichen Intelligenz in zehn Jahren KEINE Metadaten mehr benötigen werden?“ polarisierte die Diskussion. 30 % der Zuhörenden stimmten dieser Aussage zu, während 40 % der Meinung waren, dass Metadaten auch in Zukunft noch benötigt werden. Wir diskutierten Gründe dafür und dagegen, wozu auch gehörte, dass KI insbesondere bei sensiblen Daten aufgrund ethischer Aspekte den Menschen bei der Annotation der Daten nicht ersetzen kann. Wir wiesen darauf hin, dass die Erstellung von Metadaten in den Geisteswissenschaften Teil des Forschungsprozesses ist und Fachwissen erfordert. Außerdem ist die Grenze zwischen Daten und Metadaten in den Geisteswissenschaften unscharf. Bei der Verwendung von LLMs zur Erstellung von Metadaten müssen wir uns des Unterschieds zwischen von Menschen und von KI generierten Daten bewusst sein. Mit Blick auf die Zukunft stellten wir fest, dass LLMs in zehn Jahren deutlich ausgereifter sein werden, als wir uns das heute vorstellen können. Mit der Zunahme von KI-generierten Metadaten werden Fragen der Zuverlässigkeit und Verantwortung immer wichtiger, um die Originalität und Vertrauenswürdigkeit von Forschungsdaten zu gewährleisten.
Ein ausführlicherer Bericht über die Session wird gemeinsam von den Organisator:innen der Session und freiwilligen Teilnehmenden veröffentlicht. Die Präsentation der Session ist auf Zenodo verfügbar.
Über die Autor:innen:
- Anna Jacyszyn ist Postdoktorandin in der Gruppe Information Service Engineering (ISE) am FIZ Karlsruhe – Leibniz-Institut für Informationsinfrastruktur. Sie hat einen Doktortitel in Astrophysik. Anna arbeitet hauptsächlich als Koordinatorin des Leibniz-Wissenschaftscampus „Digitale Transformation der Forschung“ (DiTraRe), wo sie die Zusammenarbeit zwischen interdisziplinären Arbeitsgruppen steuert. Ein besonderer Schwerpunkt ihrer Arbeit ist AI4DiTraRe: die Untersuchung und Anwendung verschiedener KI-Methoden in vier DiTraRe-Anwendungsfällen. Sie ist auch auf LinkedIn zu finden.
- Dr. Felix Bach ist Leiter der Abteilung Forschungsdaten am FIZ Karlsruhe und wissenschaftlicher Koordinator des Leibniz ScienceCampus DiTraRe (Digital Transformation of Research). Er ist Mitleiter des NFDI4Chem-Konsortiums und engagiert sich aktiv in mehreren NFDI-Konsortien, die sich für digitale Forschungsinfrastrukturen, interdisziplinäre Datendienste und Open Science einsetzen. Seine Arbeit konzentriert sich auf die Entwicklung von Repositorien, ELNs, Datenarchivierung und KI-fähige Daten in den Natur- und Geisteswissenschaften.
- Dr. Tobias Kerzenmacher ist Forscher in der Forschungsdatenmanagementgruppe des Institut für Meteorologie und Klimaforschung (IMKASF) am Karlsruher Institut für Technologie (KIT ). Seine Arbeit konzentriert sich auf die Physik und Chemie der Atmosphäre, wobei sein besonderer Schwerpunkt auf dem Verständnis stratosphärischer Prozesse durch die Kombination von Erdsystemmodellen und Beobachtungsdaten liegt. Zu seinen wissenschaftlichen Interessen zählen großräumige atmosphärische Zirkulation – insbesondere die quasi-biennale Oszillation (QBO) – und Fragen der Forschungsintegrität. Er ist Mitglied von DiTraRe (Digital Transformation of Research) und wirkt an der Anwendung „Veröffentlichung großer Datensätze” mit.
- Mahsa Vafaie ist Doktorandin und Forscherin in der Gruppe Information Service Engineering am FIZ Karlsruhe – Leibniz-Institut für Informationsinfrastruktur. Derzeit arbeitet sie an einem Digitalisierungsprojekt, dessen Ziel es ist, einen Wissensgraphen zur Kontextualisierung historischen Wissens zu erstellen, das aus Sammlungen von Dokumenten, Aufzeichnungen und Materialien stammt, die in direktem Zusammenhang mit dem Wiedergutmachungsprozess für die Gräueltaten des nationalsozialistischen Regimes in Deutschland stehen („Themenportal zur Wiedergutmachung nationalsozialistischen Unrechts“). Darüber hinaus ist sie an wissenschaftlichen Tätigkeiten und Lehraktivitäten in den Bereichen Wissensgraphen und Semantic Web am Karlsruher Institut für Technologie (KIT) sowie auf anderen Konferenzen und Veranstaltungen in diesen Bereichen beteiligt. Sie ist auf Linkedin und Mastodon zu finden.
Open Science im Niedergang? Datenaustausch im Spannungsfeld
zwischen AI Commons und räuberische Aneignung
von Katja Mayer, Jochen Knaus und Stefan Skupien
Die Session befasste sich mit den Spannungen und Chancen bei der Aufrechterhaltung von Offenheit unter zunehmend komplexen technologischen Bedingungen und ging auf drei zentrale Fragen ein. Sie baute auf den Ergebnissen der Veranstaltung „Yes, We Are Open” auf, die im März 2025 in Berlin stattfand. (Diskussionspapier, PDF | Strategiepapier, PDF).
Frage 1 – Datenaustausch, AI Commons und räuberische Aneignung – Sind das alles alte Probleme oder Neue?
Wachsende Spannungen entstehen zwischen den Idealen der Offenheit und den Herausforderungen des KI-Zeitalters. Sicherheitsbedenken und politische Kontexte schränken die Offenheit zunehmend ein. Ein Beispiel aus Kanada veranschaulichte, dass Krankenhäuser zögern, Daten zu veröffentlichen, weil sie eine KI-gesteuerte Re-Identifizierung befürchten. Darüber hinaus bleiben Urheberrecht, geistiges Eigentum und Dateneigentum große Hindernisse für Anbietende offener Forschungsdaten. Beispielsweise remixen LLMs Material „über das Original hinaus“ und verwischen damit die Grenzen zwischen fairer Nutzung und Kreativität.
Ein immer wiederkehrendes Problem ist die mangelnde Anerkennung für Open-Data-Beitragende. Dieses wird noch verschärft, wenn KI offene Daten wiederverwendet. Eine aus den Antworten der Teilnehmenden generierte Wortwolke hielt die folgenden Spannungen fest, die von den Teilnehmenden wahrgenommen wurden: Sicherheit, Urheberrecht, Datenschutz, Anerkennung, Dual Use, Rechenschaftspflicht und Gier von Unternehmensseite.

Frage 2 – Welche Arten von Anerkennung und Unterstützung werden benötigt?
Die Teilnehmenden betonten den Mangel an strukturellen Anreizen, vor allem weil Open Data nicht als richtiger Forschungsoutput gelten. Zu den Vorschlägen gehörte die Verknüpfung von Förderungsmechanismen mit Transparenz, standardisierten Anerkennungssystemen und fachspezifischen Richtlinien. Eine zentrale Forderung war die wiederholte Betonung der Ausbildung. Darüber hinaus wurden Forderungen nach FAIRen Datendiensten, ethischen Schutzmaßnahmen und angemessenen Kooperationsmodellen laut, um Ungleichgewichte zu beseitigen, wenn akademische Daten in proprietäre KI einfließen.
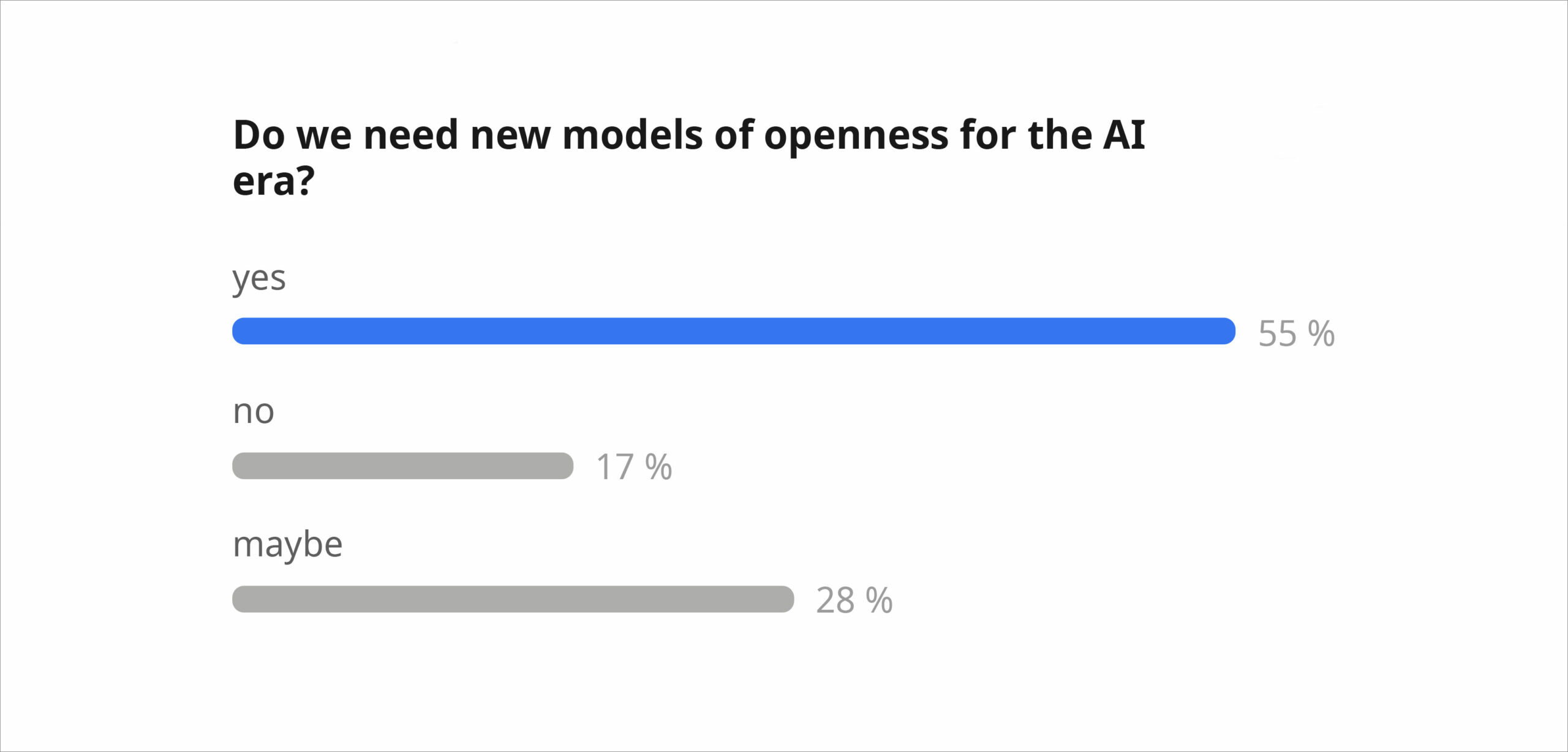
Frage 3 – Brauchen wir neue Modelle von Offenheit?
Die meisten Teilnehmenden waren sich einig, dass traditionelle Open-Science-Modelle nicht mehr zu den Realitäten von KI passen. Es wurden Forderungen nach gegenseitiger oder bedingter Offenheit mit klareren Regeln zur Rechenschaftspflicht laut. Zu den Ideen gehörten angepasste Lizenzen, kostenpflichtige kommerzielle Nutzung und kollektiv geregelter Schutz von Gemeingütern. Dennoch blieb eine starke Unsicherheit bestehen – einige waren der Meinung, dass „es bereits zu spät ist“, andere warnten davor, von der Offenheit als einem zentralen Wert der Forschung abzurücken.
Über die Autor:innen:
- Katja Mayer ist Soziologin und Wissenschafts- und Technikforscherin an der Universität Wien und hat sich auf Open-Science-Politik, digitale Infrastrukturen und KI spezialisiert. In ihrer Forschung untersucht sie kritisch, wie Datenpraktiken soziale Beziehungen mitgestalten und widerspiegeln. Mit ihrer Erfahrung sowohl in der Wissenschaft als auch in der IT-Branche integriert sie praktische und theoretische Perspektiven in ihre Lehre und ihr politisches Engagement. Sie ist außerdem leitende Wissenschaftlerin am Zentrum für Soziale Innovation (ZSI) in Wien, wo sie an partizipativen Ansätzen zur Bewertung von Citizen Science mitarbeitet.
- Jochen Knaus: Mit einem breiten Hintergrund in Informatik und Literaturwissenschaft und über 20 Jahren Erfahrung in der Life-Science-Forschung, im Forschungsdatenmanagement und in infrastrukturbezogenen Themen in großen Verbundprojekten. Er interessiert sich für alle Bereiche von Open Science und arbeitet als Referent für Forschungsinformation und KI am Weizenbaum-Institut.
- Dr. Stefan Skupien ist seit 2020 als wissenschaftlicher Koordinator für Open Science am Center for Open and Responsible Research der Berlin University Alliance tätig und verbindet dabei seine Erfahrungen in den Bereichen Forschungsmanagement, internationale Wissenschaftsstudien und Open Science.
Ein gemeinsames Verständnis und globale Wege für Open Science
und KI in neuen Forschungsumgebungen voranbringen
von Firas Al Laban und Jan Bernoth
Die Discussion Session begann mit einer Einführung des “NFDIxCS-Projekts” und einem Überblick über Möglichkeiten, ein gemeinsames Verständnis und globale Wege für Open Science und KI in neuen Forschungsumgebungen voranzubringen.
Den Rahmen setzte eine Abstimmung der Teilnehmenden über die Priorisierung der Ausgangspunkte für einen globalen Weg. Die Optionen lauteten (i) Politik und Strategien und (ii) kulturelle Einflüsse und Kompetenzaufbau.

Die Umfrageergebnisse waren knapp und umkämpft, was die Bedeutung beider Dimensionen widerspiegelte. Letztendlich wählte die Gruppe kulturelle Einflüsse und Kompetenzaufbau als bevorzugten Ausgangspunkt für gemeinsames Handeln.
Die Diskussion konzentrierte sich im Folgenden auf zwei zentrale Fragen. Die erste lautete: Wie beeinflusst Kultur die Forschung? Die Teilnehmenden tauschten viele aufschlussreiche Perspektiven aus und sprachen über die Auswirkungen kultureller Faktoren auf das Forschungsumfeld und Herausforderungen, die die internationale Zusammenarbeit behindern könnten.
Dies führte zur zweiten Frage: Könnten kulturelle Barrieren die Öffnung der Wissenschaft behindern? Die Teilnehmenden waren sich einig, dass solche Hindernisse zwar existieren, aber auch wertvolle Möglichkeiten für Lernen, Anpassung und Dialog zwischen Forschungscommunities bieten.
Es wurden mehrere praktische Maßnahmen zur Förderung des Kompetenzaufbaus in den Bereichen Open Science und KI hervorgehoben. Die Teilnehmenden betonten, dass Train-the-Trainer-Programme für die Skalierung von Fähigkeiten und Praktiken unerlässlich sind. Der Faktor Mensch – Vertrauen, Motivation und kulturelle Sensibilität – bleibt ein wichtiger Erfolgsfaktor. Gleichzeitig gewährleistet die Anpassung von Open-Access-Lehrmaterialien an lokale Kontexte, Sprachen und institutionelle Bedürfnisse eine gerechte Beteiligung.
Die Session endete mit der gemeinsamen Verpflichtung, die Bildung interessenbasierter Gemeinschaften zu fördern und einen kontinuierlichen, kooperativen Dialog über Open Science und KI in neuen Forschungsumgebungen zu etablieren.
Über die Autoren:
- Firas Al Laban ist Akademiker und Forscher mit einem soliden Hintergrund in Informatik und Mathematik. Er hat einen Doktortitel in Wissensmanagementsystemen und verfügt über internationale Erfahrung im Hochschulbereich, darunter die Lehre verschiedener Fächer, die Betreuung studentischer Forschungsarbeiten und Beiträge zu globalen Konferenzen und peer-reviewten Publikationen. Derzeit ist er wissenschaftlicher Mitarbeiter an der Universität Potsdam, wo er im Rahmen des NFDIxCS-Projekts im Bereich Forschungsdaten- und Softwaremanagement tätig ist. Seine Arbeit ist geprägt von einem starken Engagement für Innovation, Open Science und die Förderung von Technologie und Bildung durch nachhaltige, forschungsorientierte Praktiken. Er ist auf LinkedIn zu finden.
- Jan Bernoth, M.Sc., ist Informatiker und arbeitet als Forscher, Teamleiter und Doktorand am Lehrstuhl von Prof. Dr. Ulrike Lucke an der Universität Potsdam. Ausgehend von seiner Arbeit bei NFDIxCS konzentriert sich seine Forschung auf die Unterstützung des Forschungsdaten- und Softwaremanagements durch die Entwicklung der erforderlichen Architektur für den Research Data Management Container in Zusammenarbeit mit dem Konsortium und der Informatik-Community. In seiner Doktorarbeit untersucht er, wie Forschungsthemen in nicht-wissenschaftlichen Medien visualisiert werden können, um Wissenschaftler bei ihrer Wissenschaftskommunikation zu unterstützen. Folgen Sie ihm auf Mastodon.
KI im Peer-Review-Prozess: Chancen, Risiken und
Wege für die Praxis
von Johanna Havemann, Nancy Nyambura und Tim Errington
Wie könnte KI das Peer-Review-Ökosystem verändern – und möglicherweise sprengen? Das war die zentrale Frage unserer Session. Unter der gemeinsamen Leitung von Johanna Havemann (Access 2 Perspectives) und Tim Errington (Center for Open Science) und aus der Ferne unterstützt von Nancy Nyambura (Access 2 Perspectives) lud die Session zu einer Live-Ideenfindung rund um Chancen, Risiken und verantwortungsvolle Wege für die Zukunft ein. Nach kurzen Einführungsvorträgen von Johanna und Tim folgte eine Podiumsdiskussion im Hot-Seat-Format. Bei dieser wechselten sich die Podiumsteilnehmenden aus dem Publikum ab, die spontan dazu aufgefordert worden waren, Platz zu nehmen.
Die Teilnehmenden äußerten sich sowohl begeistert als auch zurückhaltend über die Vorteile und Gefahren von KI im Peer-Review-Prozess. Viele begrüßten die Möglichkeit, sprachliche Bearbeitungen zu unterstützen, formale Probleme zu erkennen, Manuskripte zusammenzufassen oder Gutachtende vorzuschlagen. Andere äußerten Bedenken hinsichtlich Voreingenommenheit, Undurchsichtigkeit, Risiken für das geistige Eigentum und der Befürchtung, dass automatisiertes Feedback das menschliche Urteilsvermögen beeinflussen oder sogar überschatten könnte. Es entstand ein starker Konsens für ein „Human-in-the-Loop”-Modells: KI kann zwar die Überprüfung und Qualitätskontrolle beschleunigen, aber die endgültige Bewertung muss weiterhin menschlicher Expertise überlassen bleiben.
Zu den vielversprechenden Anwendungsfällen gehörten die automatisierte Vorabprüfung von Preprints, die Überprüfung von Metadaten und Referenzen, die Zuordnung von Begutachtenden sowie Tools, die Autor:innen dabei helfen, ihre eigenen Arbeiten vor der Einreichung zu überprüfen. Die Teilnehmenden betonten jedoch die Notwendigkeit von Transparenz: Zeitschriften sollten offenlegen, welche Tools für welche Aufgaben eingesetzt wurden und wie Entscheidungen getroffen wurden.
Zu den ethischen Grundsätzen, die während der Session betont wurden, gehörten Fairness, Offenheit in Bezug auf Algorithmen und Prozesse, die Trennung von automatisiertem und persönlichem Feedback sowie der weiter fortbestehende Wert menschlichen kritischen Denkens. In den positiven Szenarien wurde davon ausgegangen, dass KI die Belastung der Gutachtenden verringert und die Klarheit der Manuskripte fördert; die schlimmsten Szenarien warnten vor unregulierter KI, die nicht erkennbare gefälschte Forschungsergebnisse erzeugt oder das menschliche Denkvermögen beeinträchtigt.
Die Session endete mit dem Teilen von Selbstverpflichtungen: Experimentieren mit KI-Tools, Aufnahme institutioneller Gespräche, Aktualisierung von Guidelines und Förderung einer kooperativen, verantwortungsvollen Entwicklung von KI-gestützter Begutachtung. Die Teilnehmenden erwähnten, dass sie inspiriert, nachdenklich und im Bewusstsein, dass bedeutende Fortschritte klarere Definitionen und ein gemeinsames Verständnis erfordern, weitermachen werden.
Wenn Sie mehr über die Details erfahren möchten, die während dieser Session diskutiert wurden, und weitere Informationen wünschen, um sich intensiver mit dem Thema zu beschäftigen, senden Sie eine E-Mail an .
Weiterlesen: AI in Peer Review: Fairer or Faster. A Personal Reflection by Nancy Nyambura.
Über die Autor:innen:
- Jo Havemann, PhD, ist Gründerin und CEO von Access 2 Perspectives, wo sie Schulungen und Beratung in den Bereichen Open-Science-Kommunikation und digitales Forschungsmanagement anbietet. Sie hat einen Doktortitel in Evolutions- und Entwicklungsbiologie und ist eine von der Deutschen Industrie- und Handelskammer anerkannte zertifizierte Trainerin. Jo ist außerdem Mitbegründerin und leitende Koordinatorin von AfricArXiv, einem offenen wissenschaftlichen Repositorium, das die Sichtbarkeit afrikanischer Forschung verbessert. Ihre Fachkenntnisse – darunter globale Forschungsgerechtigkeit, Open-Science-Workflows und Wissenschaftskommunikation – basieren auf Erfahrungen mit NGOs, einem Wissenschafts-Startup und dem Umweltprogramm der Vereinten Nationen.
- Nancy Nyambura steht mit über vier Jahren Erfahrung in der Leitung von gemeindebasierten Initiativen zum Kompetenzaufbau, die Frauen, Jugendliche und Menschen mit Behinderungen durch Kompetenzentwicklung und Unternehmertraining stärken, am Anfang ihrer beruflichen Laufbahn. Sie engagiert sich intensiv für die Förderung sozialer Nachhaltigkeit durch inklusive und gerechte Unterstützungssysteme. Nyambura arbeitet außerdem bei Access 2 Perspectives als wissenschaftliche Mitarbeiterin und unterstützt AfricArXiv bei der Förderung von offenem Wissen und der Einbindung von Interessengruppen im gesamten afrikanischen Forschungsökosystem, wobei ihr Schwerpunkt auf dem verantwortungsvollen Einsatz neuer Technologien in der Wissenschaft liegt. Sie ist auf LinkedIn zu finden.
- Tim Errington ist Senior Director of Research am Center for Open Science (COS), das sich für mehr Offenheit, Integrität und Reproduzierbarkeit in der wissenschaftlichen Forschung einsetzt. In dieser Position führt er gemeinsam mit Forschenden und Interessengruppen aus verschiedenen wissenschaftlichen Disziplinen und Organisationen Metawissenschaftsprojekte durch, die darauf abzielen, den aktuellen Forschungsprozess zu verstehen und Initiativen zu evaluieren, die die Reproduzierbarkeit und Offenheit wissenschaftlicher Forschung verbessern sollen. Dazu gehören groß angelegte Reproduzierbarkeitsprojekte wie das Reproducibility Project: Cancer Biology und das von der DARPA unterstützte Systematizing Confidence in Open Research and Evidence (SCORE) , sowie Evaluierungsprojekte neuer Initiativen wie Open Science Badges, Registered Reports und eine neuartige Schulung zu verantwortungsvollem Verhalten in der Forschung.
Wie FAIR-R sind Ihre Daten? Verbesserung der rechtlichen
und technischen Voraussetzungen für eine offene und KI-gestützte Wiederverwendung
von Vanessa Guzek und Katharina Miller
Während der OSC 2025 in Hamburg brachte unsere Solution Session „Wie FAIR-R sind Ihre Daten?“ rund zwanzig Teilnehmende zusammen, um reale Datensätze anhand des erweiterten FAIR-R-Frameworks zu testen – auffindbar, zugänglich, interoperabel, wiederverwendbar und verantwortungsvoll lizenziert für die Wiederverwendung durch KI. In sechs Gruppen prüften die Teilnehmenden Datensätze wie Open Images, Dryad, UK Data Service, FDZ-Bildung und GoTriple-Metadaten.
Die Teams unterzogen die FAIR-R-Checkliste einem Stresstest und identifizierten dabei wiederkehrende Hindernisse: fehlende oder verstreute Lizenzen, NC/ND-Beschränkungen, unklare Rechte Dritter, unklare Herkunft und fehlende maschinenlesbare Lizenz- oder Metadatenfelder. Auch ethische und DSGVO-Aspekte fehlten häufig bei menschlichen oder qualitativen Daten.
Die Teilnehmenden schlugen konkrete Verbesserungen vor: die Zusammenführung von für Menschen und Maschinen lesbaren Lizenzen (SPDX/schema.org), die Hinzufügung expliziter Ethik- und Datenschutzprüfungen, die Klärung der Urheberschaft und Zitierweise auf Sammlungsebene sowie eine Stärkung von Strategien zur Speicherung in Repositorien und von PID. Die überarbeitete FAIR-R-Checkliste v1.1 wird diese in der Gruppe erarbeiteten validierten Verbesserungen enthalten.
Zusammenfassend lässt sich sagen, dass keiner der überprüften Datensätze die FAIR-Prinzipien vollständig erfüllte – und somit auch nicht FAIR-R. Die Session zeigte, dass FAIR zwar notwendig ist, FAIR-R jedoch unerlässlich ist, um Open Data rechtlich einwandfrei, maschinenlesbar und vertrauenswürdig für die Wiederverwendung durch KI zu machen.
Die Struktur der Session, die Folien und die FAIR-R-Checkliste sind auf Zenodo verfügbar. Der Sessionbericht, die FAIR-R-Checkliste v1.1 und die Mini-Audit-„Snapshots“ werden ebenfalls dort veröffentlicht.
Über die Autorinnen:
- Vanessa Guzek Hernando ist als Rechtsanwältin in Deutschland und Spanien zugelassen und verfügt über mehr als zehn Jahre Erfahrung in den Bereichen geistiges Eigentumsrecht, internationale Rechtsrahmen und Politikentwicklung. Sie kam zu Miller International Knowledge (MIK) als Rechts- und Politikdirektorin für IP4OS, wo sie strategische Rechtsinitiativen an der Schnittstelle zwischen geistigem Eigentum und Open Science leitet. Seit Beginn ihrer Anwaltstätigkeit im Jahr 2013 hat sich Vanessa auf grenzüberschreitende Rechtsstrategien, Compliance und regulatorische Rahmenbedingungen spezialisiert. Dank ihrer fundierten Kenntnisse im internationalen Privatrecht, Vertriebsrecht und Haftungsrecht ist sie in der einzigartigen Lage, innovatives IP-Management in offenen Forschungsumgebungen zu unterstützen und mitzugestalten.
- Katharina Miller ist eine versierte Juristin und Expertin für Rechtskonformität, Corporate Governance und Nachhaltigkeit mit über 15 Jahren Berufserfahrung. Als Partnerin bei Miller International Knowledge (MIK) ist sie auf die Angleichung von Geschäftspraktiken an internationale Standards spezialisiert, wobei ihr Schwerpunkt auf geistigem Eigentum (IP), Ethik und Unternehmensverantwortung liegt. Katharina ist eine erfahrene Pädagogin und Beraterin, die sich aktiv an Projekten zum Kompetenzaufbau wie IP4OS beteiligt, wo sie ihr Fachwissen einbringt, um die Synergie zwischen IP und Open Science zu fördern. Sie war als Arbeitspaket- und Aufgabenleiterin für ethische Rahmenbedingungen in EU-finanzierten Projekten tätig, darunter H2020 Path2Integrity oder H2020 DivAirCity, und ist eine vertrauenswürdige Beraterin für Datenschutz und Einhaltung gesetzlicher Vorschriften. Katharina engagiert sich leidenschaftlich für die Förderung von Innovation, verantwortungsvoller Governance und Inklusion und setzt sich konsequent für nachhaltige und ethische Geschäftspraktiken auf internationaler Ebene ein.
Marbles – Upcycling von Forschungsabfällen und optimale
Nutzung aller Arbeiten im Zeitalter von Open Science
von Pablo Hernández Malmierca und Isabel Barriuso Ortega
Die Gründer von Research Agora, einer innovativen Plattform zur Anerkennung unsichtbarer Forschungsergebnisse, stellten ihr neuartiges Publikationsformat Marbles vor. Die Session begann mit einem Überblick über zwei wichtige Herausforderungen in der Forschung: Forschungsabfälle und die Reproduzierbarkeitskrise bei Forschungsartikeln. Anschließend ging es darum, wie diese Probleme im aktuellen Rahmen von Open Science und einer Reform der Bewertung angegangen werden können.
Als Lösung für diese Probleme wurden Marbles vorgeschlagen. Dabei handelt es sich um kurze, peer-reviewte und im Open Access zugängliche Berichte. Diese sind mit bereits veröffentlichter Literatur verknüpft und berichten über Forschungsergebnisse, die im Rahmen der Forschung routinemäßig anfallen, aber nicht in den traditionellen Artikel passen: Replikationen, fehlgeschlagene Replikationen, alternative Methoden, explorative Hypothesen und negative Ergebnisse. Marbles haben das Potenzial, die in Forschungsartikeln berichteten Informationen gemeinsam zu ergänzen und deren Reproduzierbarkeit und Wirkung zu messen. Außerdem würdigen sie die unsichtbare Arbeit von Forschenden, die diese Experimente durchführen, de rvon Begutachtenden, die diese Veröffentlichungen überprüfen, und von den Autor:innen der verlinkten Artikel, die Metriken zur Qualität ihrer veröffentlichten Forschungsergebnisse erhalten.
Im Anschluss an die Präsentation diskutierten die Teilnehmenden lebhaft darüber, wie wichtig eine Ergänzung dieser Gemeinschaftsinitiative durch eine Strategie von Forschungseinrichtungen und Förderorganisationen ist. Die gemeinsamen Anstrengungen sollten sich darum bemühen, Forschungsverschwendung zu reduzieren, die Reproduzierbarkeit zu verbessern und die Anerkennung vielfältiger Ergebnisse zu unterstützen. Abschließend wiesen sie darauf hin, dass die Aufnahme von Marbles in Aggregatoren (zum Beispiel OpenAlex, OpenAIRE oder PubMed) und Anreize zur Veröffentlichung dieser Art von Ergebnissen wichtige Faktoren für den langfristigen Nutzen sind.
Die Folien und der Bericht zu dieser Session sind auf Zenodo verfügbar.
Über die Autor:innen:
- Pablo Hernández Malmierca ist CEO und Mitbegründer von Research Agora, einer Plattform zur Förderung eines zugänglicheren, transparenteren und kooperativeren Forschungsökosystems. Er hat einen Doktortitel in Stammzellenbiologie und Immunologie (Universität Heidelberg) und verfügt über mehr als 10 Jahre Forschungserfahrung in Spanien, Großbritannien, der Schweiz und Deutschland. Er kennt sich bestens mit der akademischen und industriellen Forschung aus und ist Autor wichtiger Publikationen. Er wollte schon immer Forscher werden, aber jetzt gilt seine Leidenschaft der Verbesserung der Forschungskultur weltweit. Sie finden ihn auf LinkedIn.
- Isabel Barriuso Ortega ist COO und Mitbegründerin von Research Agora, einer Plattform zur Förderung eines zugänglicheren, transparenteren und kooperativeren Forschungsökosystems. Sie hat einen Doktortitel in Neurowissenschaften von der Universität Heidelberg. Mit über 8 Jahren Berufserfahrung in Spanien, Frankreich und Deutschland ist sie Autorin wichtiger Publikationen zur Systemneurowissenschaft. Sie ist eine erfahrene Datenanalystin und begeistert sich für Wissenschaftskommunikation. Isabel ist außerdem aktives Mitglied von AMIT-MIT, wo sie sich für die Förderung der Gleichstellung der Geschlechter und den Abbau von Diskriminierung in der Forschung und im MINT-Bereich einsetzt. Sie ist auf Bluesky und Linkedin zu finden.
Open Science Capacity Building in Zeiten von KI:
Lösungen finden mit GATE
von Anika Müller-Karabil und Marie Alavi
Über 40 Teilnehmende aus den Bereichen Forschung, Bildung, Bibliotheken, Daten und Software sowie aus politischen Institutionen und Fördereinrichtungen nahmen an der GATE-Session teil, um zu erörtern, wie Open Science an der Schnittstelle mit KI gedeihen kann. Die Session stützte sich auf Materialien und Daten aus dem Open Science Learning GATE, das eine Infrastruktur für den kontinuierlichen Wissensaustausch über Open Science bietet, verschiedene Interessengruppen miteinander verbindet und Orientierungshilfen zu aktuellen Entwicklungen gibt.
Die Teilnehmenden entwickelten in sieben multidisziplinären Gruppen gemeinsam zielgruppenspezifische Maßnahmen zum Aufbau von Open-Science-Kompetenzen. Dabei nutzten sie von GATE bereitgestellte Personas (zum Beispiel Nachwuchsforschende, Programmbeauftragte) und Leitgedanken (etwa vorurteilsfreie KI, Datenschutz), um ihre Diskussionen zu fokussieren.
Die Gruppen schlugen konzeptionelle Leitlinien vor und identifizierten Bedürfnisse statt umsetzungsreifer Lösungen, wobei sie Prioritäten hervorhoben, die für alle Communities gelten. Dazu gehörten der Aufbau von Vertrauen und Transparenz, die frühzeitige Einbettung von Open Science in die Forschungsausbildung, die Förderung flexibler, fachspezifischer Rahmenbedingungen und die Gewährleistung eines verantwortungsvollen Einsatzes von KI-Tools. Die Forschenden betonten die Integration von Open Science in die Ausbildung und die Abstimmung von Motivation und Anreizen. Bibliothekar:innen und Pädagog:innen hoben ihre Brückenfunktion hervor und unterstützten praktische Leitlinien und den ethischen Einsatz von KI. Technische Expert:innen konzentrierten sich auf Reproduzierbarkeit und zuverlässige Infrastrukturen, während Akteur:innen aus Politik und Finanzierung Kohärenz, Machbarkeit und nachhaltige Unterstützung betonten.
Die Session bekräftigte, dass die Förderung von Open Science in einer von KI getriebenen (Forschungs-)Landschaft gemeinsames Handeln aller Communities erfordert. Die Nutzung der Mission und der Ressourcen von GATE ermöglicht es den Interessengruppen, die Praxis mit der Politik zu verbinden und gemeinsam Strategien zu entwickeln, die Open Science voranbringen und sowohl prinzipientreu sind und auch praktisch umsetzbar.
Die Struktur und die Folien der Session sind auf Zenodo verfügbar, und der Sessionbericht wird ebenfalls dort veröffentlicht.
Über die Autorinnen:
- Anika Müller-Karabil arbeitet als wissenschaftliche Mitarbeiterin an der Universität Bremen den Sprachzentren der Universitäten in Bremen. Sie ist Expertin auf dem Gebiet des Sprachunterrichts, des Sprachenlernens und der Sprachprüfung. Zu ihren Forschungsinteressen gehören akademische Sprachanforderungen im Hochschulbereich, Sprachunterricht im Kontext von KI und Open Science. Anika ist Mitentwicklerin von GATE und Mitglied des Netzwerks für Bildungs- und Forschungsqualität (NERQ).
- Marie Alavi ist wissenschaftliche Mitarbeiterin an der Universität Kiel. Ihr Forschungsschwerpunkt liegt an der Schnittstelle zwischen verantwortungsvoller Forschung, Open Science, geistigem Eigentum und KI. Sie ist Mitentwicklerin von GATE und Mitglied des Netzwerks für Bildungs- und Forschungsqualität (NERQ), wo sie die Interessengruppen zu Open Science (wo GATE seinen Ursprung hat) und Open Science & geistiges Eigentum mitleitet. Derzeit ist Marie an der IP4OS-Initiative beteiligt. Zuvor war sie an den Initiativen Path2Integrity und HAnS beteiligt, wo sie sich mit Forschungsintegrität und der Rolle von KI im Hochschulbereich befasste.
KI, Plagiate und Textrecycling: Informationsressourcen
für akademische Autor:innen
von Aysa Ekanger
Welche Anwendungsfälle generativer KI sollten bei wissenschaftlichen Artikeln erlaubt sein, wie sollte der Einsatz im redaktionellen Prozess deklariert werden und welche urheberrechtlichen und ethischen Überlegungen sind damit verbunden? Die Herausforderungen, die generative KI mit sich bringt, gesellen sich zu älteren Problemen, die ebenfalls Urheberrecht und Ethik betreffen können und mit denen Redakteur:innen und Autor:innen besser vertraut sein sollten: nämlich Plagiate und Textrecycling (sogenanntes Selbstplagiat).
In dieser Solution Session befassten sich die Teilnehmenden damit, wie Zeitschriften akademischen Autor:innen mit ihrem Wissen über die Probleme von Plagiaten und Textrecycling helfen können, einen problematischen Einsatz generativer KI in ihren Manuskripten zu vermeiden. Die Teilnehmenden mussten eine der vorbereiteten Aufgaben bearbeiten, um Informationsressourcen, ein Flussdiagramm, FAQ oder eine Liste von Themen zu erstellen, die in einer Journal Policy behandelt werden sollten, und ihnen lagen Auszüge aus den Living Guidelines zum verantwortungsvollen Einsatz generativer KI in der Forschung und dem Text Recycling Research Project als Referenz vor.
In ihren Lösungsvorschlägen betonten die Teilnehmenden die Bedeutung von Transparenz und menschlicher Kontrolle. Zu den konkreten Maßnahmen, die zur Erhöhung der Zuverlässigkeit von Forschungsarbeiten bei Verwendung von GenAI-Tools vorgeschlagen wurden, gehörten eine standardisierte Erklärung zur Verwendung von KI, die Aufnahme von DOIs in die Referenzlisten (um das Problem der Referenzhalluzinationen zu mindern) und die Verwendung von Wissensgraphen als Mittel zur Verhinderung von Ideenplagiaten.
Die Session lieferte keine Ergebnisse, die von den Redaktionsteams der Zeitschriften direkt eingesetzt werden können, aber sie bot nützliche Einblicke für die Präsentation dieser Themen in Workshops für Zeitschriftenredakteure, die ihre Policies um den Einsatz von KI erweitern möchten. Die Materialien der Session sind auf Zenodo verfügbar.
Über die Autorin:
- Aysa Ekanger ist Koordinatorin von Septentrio Academic Publishing, einem Diamond-OA-Journal-Verlagsdienst an der UiT The Arctic University of Norway. Im Septentrio-Team ist sie für den Benutzer-Support und die Schulung von Redakteur:innen zuständig. Außerdem ist sie eine der Expert:innen der Universitätsbibliothek für Creative-Commons-Lizenzen und beschäftigt sich mit anderen Fragen im Zusammenhang mit Open Access. Aysa hat einen Doktortitel in Theoretischer Linguistik von der Universität Groningen in den Niederlanden. Sie ist auf Bluesky und LinkedIn zu finden.
Podiumsdiskussion “The Role of Open Science
in Safeguarding the Research Enterprise”
von Tim Errington
In einer Podiumsdiskussion zum Thema „The role of Open Science in safeguarding the research enterprise” starteten die Panelteilnehmenden, Julia Prieß-Buchheit von der Universität Kiel, Jez Cope von der British Library und Peter Suber von der Harvard Library (per Videokonferenz zugeschaltet), mit kurzen Impulsstatements. Darin hoben sie die vielfältigen Bedrohungen für die Forschung hervor, die von der unbeabsichtigten Verwendung von Forschungsinhalten und der Erstellung gefälschter Inhalte bis hin zum politischen Einfluss auf den Forschungsprozess und die Forschungsergebnisse reichen.
Im Anschluss an die Impulsstatements wurde die Diskussion anhand von vier Leitfragen strukturiert. Diese reichten von Resilienz, über den Beitrag von Konzepten wie Open Data und Open Access sowie von offenen Prozessen wie Open Peer Review zur Glaubwürdigkeit bis hin zu Strategien wie dem Schutz geistigen Eigentums, mit denen ein Gleichgewicht zwischen den Prinzipien von Open Science und der Notwendigkeit des Schutzes von Inhalten hergestellt werden kann. Fragen aus dem Publikum halfen dabei, die Diskussion zu lenken. Die Diskussion umfasste, wie Redundanz im Forschungsökosystem aufgebaut werden kann, wie beispielsweise das von der TIB eingerichtete Dark Archive von arXiv, aber auch, wie Skeptiker:innen und politischen Entscheidungsträger:innen der Wert von Open Science vermittelt werden kann. Es wurde deutlich, dass global geteilte Wissenschaft schwieriger zu zensieren ist und zu einer widerstandsfähigeren Forschungslandschaft beitragen kann.
Über den Autor:
- Tim Errington ist Senior Director of Research am Center for Open Science (COS), das sich für mehr Offenheit, Integrität und Reproduzierbarkeit in der wissenschaftlichen Forschung einsetzt. In dieser Position führt er gemeinsam mit Forschenden und Interessengruppen aus verschiedenen wissenschaftlichen Disziplinen und Organisationen Metawissenschaftsprojekte durch, die darauf abzielen, den aktuellen Forschungsprozess zu verstehen und Initiativen zu evaluieren, die die Reproduzierbarkeit und Offenheit wissenschaftlicher Forschung verbessern sollen. Dazu gehören groß angelegte Reproduzierbarkeitsprojekte wie das Reproducibility Project: Cancer Biology und das von der DARPA unterstützte Systematizing Confidence in Open Research and Evidence (SCORE) , sowie Evaluierungsprojekte neuer Initiativen wie Open Science Badges, Registered Reports und eine neuartige Schulung zu verantwortungsvollem Verhalten in der Forschung.




Open Science & KI: Nicht das Ende – nur der Anfang
Die Open Science Conference brachte Teilnehmende verschiedener Disziplinen und Karrierestufen zusammen. Die ausgesprochen konstruktive Atmosphäre zeigte sich darin, dass sich die Teilnehmenden trotz Kontroversen um OS und KI sehr engagierten, Annahmen in Frage stellten und gemeinsam konkrete Lösungen für reale Probleme entwickelten. Die Veranstaltung machte sowohl die Dringlichkeit und Relevanz des Themas deutlich als auch, wie viel noch ungeklärt ist. Anstatt einen Abschluss zu bilden, fühlte sich die OSC 2025 eher wie ein Anfang an: eine gemeinsame Verpflichtung, den Dialog und die Zusammenarbeit fortzusetzen und die technologischen, ethischen und pädagogischen Fragen voranzutreiben, die eine offene, vertrauenswürdige KI und Open Science prägen werden.
Materialien wie Präsentationen, Zusammenfassungen der Sessions und Poster sind auf Zenodo veröffentlicht. Aufzeichnungen der Keynotes, Podiumsdiskussionen und Präsentationen der Discussion Sessions sind auf YouTube verfügbar.
Das könnte Sie auch interessieren:
- ZBW-Pressemitteilung: „Open Science Conference zeigt: Vertrauenswürdige KI braucht offene und nachvollziehbare Daten”
- Open-Access-Tage 2025: Ziel erreicht – oder wie kann es (jemals) gelingen?
- Barcamp Open Science 2025: Von Bedrohungen hin zur kollektiven Resilienz
- Ambitionierte Vorreiterin für Open Science: Das sind die Top-Prioritäten bei der EOSC Association


Neue Räume für Arbeit 4.0 und Lernen 4.0: Auswirkungen für das Bildungssystem?

Open Educational Resources auffindbar machen: Das Suchtool OER-Hörnchen

Science 2.0: Chance oder lästiges Übel?
View Comments

KI in Bibliotheken: Wie Bibliotheken ihrer Verantwortung gerecht werden können
Wie können Bibliotheken angesichts großer Potenziale, aber auch beträchtlicher...