
Coding da Vinci 2018: Hackathon mit Open Data aus Forschung und Kultur
Mit einem Kick-off-Event ist Coding da Vinci Rhein-Main 2018 gestartet. An dem Hackathon rund um offene Daten aus Kultur- und Forschungsinstitutionen beteiligt sich erstmals die ZBW als Datengeberin. Wir geben einen Kurzbericht vom Kick-off und dem verfügbar gemachten Bestand an Open Data der ZBW.
von Birgit Fingerle und Joachim Neubert (ZBW)
Mit einem Kick-off am 27. und 28. Oktober in der Johannes-Gutenberg-Universität Mainz fiel der Startschuss für die sechste Auflage des Hackathons „Coding da Vinci“. Ausgerichtet wird der Hackathon dieses Mal von Kultureinrichtungen aus dem Rhein-Main-Gebiet.

Über einen Zeitraum von fünf Wochen sind nun unter anderem an Kultur, Technik, Design und Games Interessierte aus ganz Deutschland aufgerufen, aus offenen Daten aus Kultur- und Forschungsinstitutionen kreativ etwas Neues zu schaffen. Aus den Sammlungen digitaler Ton- und Videoaufnahmen, von Bildern und Metadaten sollen so Anwendungen entstehen, die in Kultur und Gesellschaft genutzt werden können.
Hackathons als Teil der weltweit wachsenden OpenGLAM-Bewegung
Coding da Vinci – Der Kultur-Hackathon ist ein Gemeinschaftsprojekt der Deutschen Digitalen Bibliothek, der Forschungs- und Kompetenzzentrum Digitalisierung Berlin (digiS), der Open Knowledge Foundation Deutschland und Wikimedia Deutschland.
Skip to PDF contentIm Gegensatz zu klassischen Hackathons erstrecken sich die Coding-da-Vinci-Hackathons über den Zeitraum mehrerer Wochen. Coding-da-Vinci-Hackathons werden seit 2014 veranstaltet. Bislang haben daran bereits über 400 Personen teilgenommen und rund 70 digitale Anwendungen umgesetzt. Dazu zählten mobile Apps, interaktive Installationen, Augmented-Reality-Anwendungen bis hin zu Hardware-Prototypen. Die Hackathons werden als Teil der weltweit wachsenden OpenGLAM-Bewegung gesehen, die sich für den freien Zugang zu und die offene Nachnutzung von digitalisierten Kulturgütern einsetzt.
Kick-off eröffnet Sprint-Phase
Beim Kick-off in der Alten Mensa der Johannes-Gutenberg-Universität in Mainz stellten die 23 Datengeber aus Museen, Archiven und Bibliotheken ihre offenen Datensets vor. Diese reichten von Filmen zum Thema Krieg und Alltag in Deutschland (1914-1918) über wirtschaftsgeschichtliche Texte zu Unternehmen aus Rheinland-Pfalz oder hochauflösende Rundumaufnahmen von Kleidern verschiedener Epochen bis hin zu Posthornklängen aus den Beständen des Frankfurter Kommunikationsmuseums.
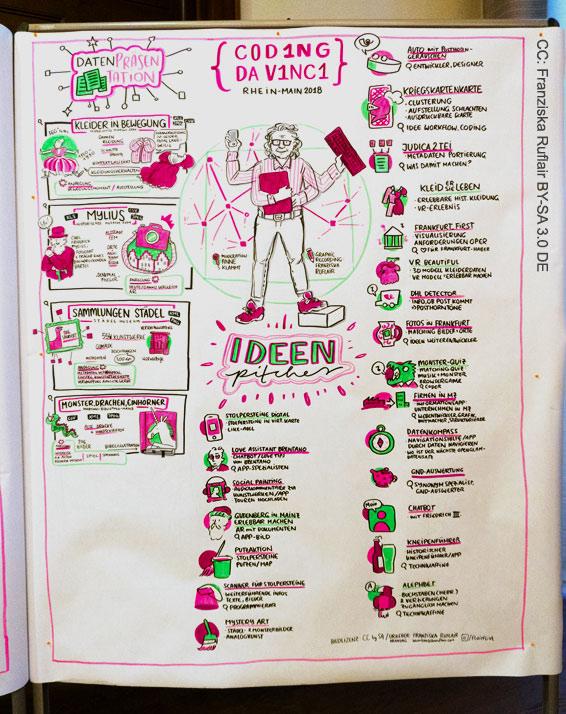
Aus dem Kreis der über 100 Teilnehmenden wurden Ideen formuliert und mit 22 Vorschlägen in Projektpitches vorgestellt. Gruppen fanden sich zusammen, um einzelne Ideen weiter zu diskutieren und erste Prototypen zu hacken. Der großzügige zeitliche Rahmen bot viel Gelegenheit zum direkten Kontakt und auch zum Austausch der Datengeber untereinander, so dass Überschneidungen in den Datenbeständen ausgelotet und Möglichkeiten der Zusammenarbeit identifiziert werden konnten.
Die Teams, die sich beim Kick-off zusammengefunden haben, entwickeln nun innerhalb weniger Wochen ihre Ideen bis zum lauffähigen Prototypen. Aber auch für diejenigen, die nicht nach Mainz kommen konnten, ist ein Einstieg noch möglich und erwünscht. Die Sprint-Phase dauert fünf Wochen. In einer Preisverleihung im Landesmuseum Mainz werden am 1. Dezember die spannendsten Anwendungen in unterschiedlichen Kategorien prämiert.
Forschungsdatenbestände der Pressearchive unter offener Lizenz
Beim aktuellen Hackathon gehört erstmals auch die ZBW zu den Datengebern. Sie beteiligt sich mit den Personen- und Firmendossiers der „Pressemappe 20. Jahrhundert“.

In ihren Pressearchiven in Kiel und Hamburg haben die ZBW beziehungsweise ihre Vorläuferinstitutionen über fast hundert Jahre hinweg Material zu Personen, Firmen/Institutionen, Waren und Sachthemen aus über 1.500 Publikationen gesammelt und zu themenbezogenen Dossiers zusammengestellt. Die bis 1948 veröffentlichten Dokumente mit circa 5,7 Mio. Seiten wurden in einem von der DFG geförderten Projekt digitalisiert. Sie wurden nach und nach mit entsprechenden Metadaten erschlossen und über die Anwendung „Pressemappe 20. Jahrhundert“ (PM20) öffentlich zur Verfügung gestellt. DFG-Viewer-Links führen direkt zur Dossieransicht – zum Beispiel für Mahatma Gandhi oder die Hamburg-Bremer Afrika Linie AG.
Für zeitgeschichtlich und kulturell Interessierte bieten die ZBW-Pressearchive einen breitgefächerten Einblick in die zeitgenössische Wahrnehmung des 20. Jahrhunderts. Zugleich bilden sie einzigartige Forschungsdatenbestände für Sozial- und Wirtschaftshistoriker, für Medienwissenschaft und Unternehmensgeschichte. Die ZBW, die vor allem der Unterstützung der aktuellen wirtschaftswissenschaftlichen Forschung verpflichtet ist, öffnet diese Datenbestände daher für die Nutzung unterschiedlicher Communities. Als einen ersten Schritt hat sie dafür die gesamten Metadaten unter CC0-Lizenz gestellt, um eine offene und freie Nachnutzung zu ermöglichen. Die Veröffentlichung der Daten in dokumentierten und nachnutzbaren Formaten – wie hier JSON-LD – ist ebenfalls Teil dieser Community-Öffnung. Ein ad-hoc-Datenabgleich mit der Kollegin vom Fachinformationsdienst Jüdische Studien brachte überraschend viele gemeinsame Treffer mit dem Portal JudaicaLink, die künftig zur Anreicherung der dortigen Datensets genutzt werden sollen.
Der ZBW-Datensatz für „Coding da Vinci“ ist per DOI herunterladbar und zitierbar. Er wird begleitet von einem Github Repository für Code-Beispiele und Feedback. Die Daten sind durch kontrollierte Vokabulare erschlossen und bieten zahlreiche Links zur GND und zu Wikidata/Wikipedia – und damit beste Voraussetzungen für Mashups mit anderen Beständen, besonders natürlich auch solche aus der Linked Data Cloud.


Toolsammlungen: Die passenden Tools für digitale Zusammenarbeit und Lernen auswählen

Open Science: Ein Kernthema für die Europäische Kommission

Open Economics Guide: Neue Open-Science-Unterstützung für Wirtschaftsforschende
View Comments

Open-Access-Tage 2018 – Teil II: Wie entwickelt sich Open Access in einzelnen Fächern und Projekten?
Bei den Open-Access-Tagen 2018 ging es um Themen wie die Umsetzung von Open Access...